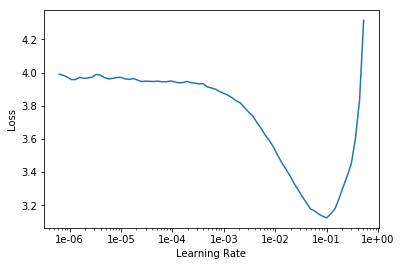
The idea for a learning rate range test as done in lr_find comes from this paper by Leslie Smith: https://arxiv.org/abs/1803.09820 That has a lot of other useful tuning tips; it's worth studying closely.
In lr_find, the learning rate is slowly ramped up (in a log-linear way). You don't want to pick the point at which loss is lowest; you want to pick the point at which it is dropping fastest per step (=net is learning as fast as possible). That does happen somewhere around the middle of the downward slope or 1e-2, so the guy who wrote the notebook has it about right. Anything between 0.5e-2 and 3e-2 has roughly the same slope and would be a reasonable choice; the smaller values would correspond to a bit slower learning (=more epochs needed, also less regularization) but with a bit less risk of reaching a plateau too early.
I'll try to add a bit of intuition about what is happening when loss is the lowest in this test, say learning rate=1e-1. At this point, the gradient descent algorithm is taking large steps in the direction of the gradient, but loss is not decreasing. How can this happen? Well, it would happen if the steps are consistently too large. Think of trying to get into a well (or canyon) in the loss landscape. If your step size is larger than the size of the well, you can consistently step over it every time and end up on the other side.
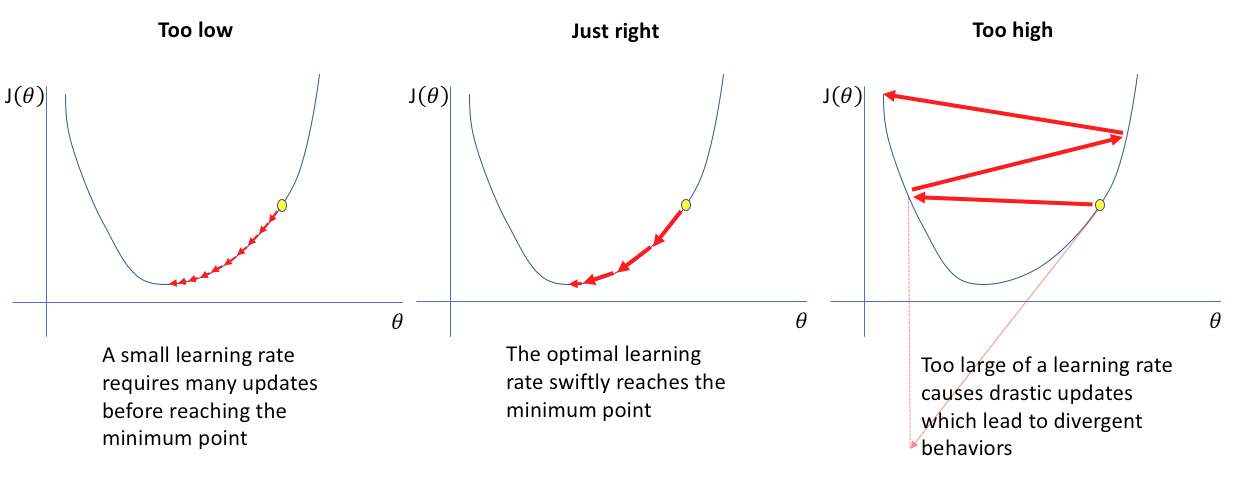
This picture from a nice blog post by Jeremy Jordan shows it visually:
![enter image description here]()
In the picture, it shows the gradient descent climbing out of a well by taking too large steps (maybe lr=1+0 in your test). I think this rarely happens exactly like that unless lr is truly excessive; more likely, the well is in a relatively flat landscape, and the gradient descent can step over it, not being able to get into the well in the first place. High-dimensional loss landscapes are hard to visualize, and may be very irregular, but in a sense the lr_find test is looking for the scale of the typical features in the landscape and then picking a learning rate that gives you a step which is similar sized but a bit smaller.