(This post is continuation of my previous question on divisive hierarchical clustering algorithm.)
The problem is how to implement this algorithm in Python (or any other language).
Algorithm description
A divisive clustering proceeds by a series of successive splits. At step 0 all objects are together in a single cluster. At each step a cluster is divided, until at step n - 1 all data objects are apart (forming n clusters, each with a single object).
Each step divides a cluster, let us call it R into two clusters A and B. Initially, A equals R and B is empty. In a first stage, we have to move one object from A to B. For each object i of A, we compute the average dissimilarity to all other objects of A:
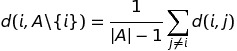
The object i' for which equation above attains its maximal value will be moved, so we put

In the next stages, we look for other points to move from A to B. As long as A still contains more than one object, we compute

for each object i of A and we consider the object i'' that maximizes this quantity. When the maximal value of the equation above is strictly positive, we move i'' from A to B and then look in the new A for another object that might be moved. On the other hand, when the maximal value of the difference is negative or 0 we stop the process and the division of R into A and B is completed.
At each step of the divisive algorithm we also have to decide which cluster to split. For this purpose we compute the diameter
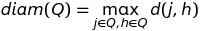
for each cluster Q that is available after the previous step, and choose the cluster for which diameter is largest.
My starting code is pasted below. Actually the script returns ValueError: list.remove(x): x not in list.
# Dissimilarity matrix
dm = [
[ 0, 2, 6, 10, 9],
[ 2, 0, 5, 9, 8],
[ 6, 5, 0, 4, 5],
[10, 9, 4, 0, 3],
[ 9, 8, 5, 3 ,0]]
# Create splinter and remaining group
splinter = []
remaining = range(len(dm))
# Find record ra that has the greatest average distance from the rest of the records
ra = 0
dMax = -999
for i in range(len(dm)):
dSum = 0
for j in range(len(dm)):
if i == j:
continue
dSum += dm[i][j]
if dMax < dSum:
dMax = dSum
ra = i
splinter.append(ra)
remaining.remove(ra)
# Check every record in remaining and moves the record if record is closer to splinter
bChanged = True
while bChanged:
bChanged = False
for i in range(len(remaining)):
d1 = 0.0
for j in range(len(splinter)):
d1 += dm[i][j]
d1 /= float(len(splinter))
d2 = 0.0
for k in range(len(remaining)):
if i == k:
continue
d2 += dm[i][k]
if len(remaining) > 1:
d2 /= (len(remaining) - 1.0)
if d1 < d2:
bChanged = True
splinter.append(i)
remaining.remove(i)
break