I've been testing the ECS's rolling updates in DAEMON mode and I'm not able to avoid occasional "502 Bad Gateway" responses. Here is what I did to test this which seems to point at a bug in the draining strategy process.
To start, I wrote a minimal hello-world program in Kotlin/Jersey that responds to curl GET (source). I hit the endpoint in a loop every ~300ms:
while [ 1 ]; do curl -s http://...us-east-2.elb.amazonaws.com/helloWorld | ts '[%Y-%m-%d %H:%M:%S]'; echo ""; sleep 0.3; done
Next, I push a new container image (using the same tag) that produces a slightly different response (110 vs 1010) so I can observe the roll-out progress. Finally I force the service update with:
aws ecs update-service --service service-helloworld-jersey --cluster cluster-helloworld-jersey --force-new-deployment
I have two tasks in my service and 50% in Minimum healthy percent. The Bash loop produces the following output during the rolling updates - at some point there are two outputs, one with "110" (old code), and the other with "1010" (new code), this is after one of the containers has been updated and the other one still has not:
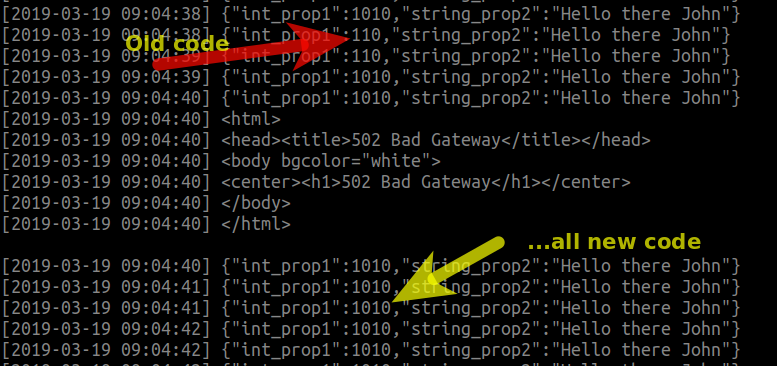
If you correlate the events on the Bash console with the events in the AWS console (both are NTP-time-synced), you can see that around 9:04:39 we are still hitting the old code/container despite the "draining" event supposedly occurring since 9:04:28 which I highlighted in red below. At 9:04:39 the task is finally stopped which correlates with the "502 Bad Gateway" response in the loop.
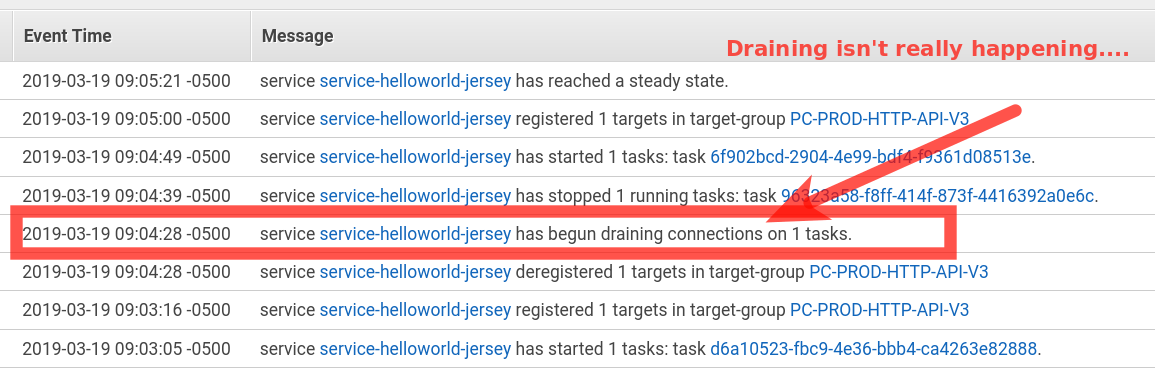
My conclusion is that the ELB isn't draining the last target correctly which results in the error we see.
If anyone has any thoughts how to diagnose this further or configure differently, please let me know.
I was able to avoid any service interruption by increasing the ELB's deregistration delay from 10s to 30s.
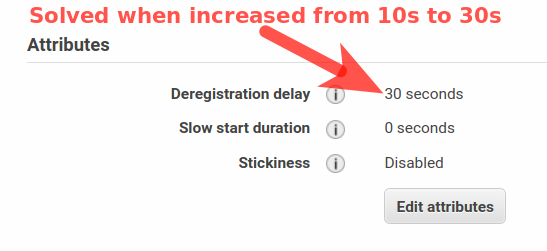
Elastic Load Balancing stops sending requests to targets that are deregistering. What does moving the delay to 30s actually do? – Immunogenetics