I coded a little program that measures the time spent into a loop (via an inline Sparc assembly code snippet).
Everything is right until I set number of iterations above roughly 4.0+9 (above 2^32).
Here's the code snippet :
#include <stdio.h>
#include <sys/time.h>
#include <unistd.h>
#include <math.h>
#include <stdint.h>
int main (int argc, char *argv[])
{
// For indices
int i;
// Set the number of executions
int nRunning = atoi(argv[1]);
// Set the sums
double avgSum = 0.0;
double stdSum = 0.0;
// Average of execution time
double averageRuntime = 0.0;
// Standard deviation of execution time
double deviationRuntime = 0.0;
// Init sum
unsigned long long int sum = 0;
// Number of iterations
unsigned long long int nLoop = 4000000000ULL;
//uint64_t nLoop = 4000000000;
// DEBUG
printf("sizeof(unsigned long long int) = %zu\n",sizeof(unsigned long long int));
printf("sizeof(unsigned long int) = %zu\n",sizeof(unsigned long int));
// Time intervals
struct timeval tv1, tv2;
double diff;
// Loop for multiple executions
for (i=0; i<nRunning; i++)
{
// Start time
gettimeofday (&tv1, NULL);
// Loop with Sparc assembly into C source
asm volatile ("clr %%g1\n\t"
"clr %%g2\n\t"
"mov %1, %%g1\n" // %1 = input parameter
"loop:\n\t"
"add %%g2, 1, %%g2\n\t"
"subcc %%g1, 1, %%g1\n\t"
"bne loop\n\t"
"nop\n\t"
"mov %%g2, %0\n" // %0 = output parameter
: "=r" (sum) // output
: "r" (nLoop) // input
: "g1", "g2"); // clobbers
// End time
gettimeofday (&tv2, NULL);
// Compute runtime for loop
diff = (tv2.tv_sec - tv1.tv_sec) * 1000000ULL + (tv2.tv_usec - tv1.tv_usec);
// Summing diff time
avgSum += diff;
stdSum += (diff*diff);
// DEBUG
printf("diff = %e\n", diff);
printf("avgSum = %e\n", avgSum);
}
// Compute final averageRuntime
averageRuntime = avgSum/nRunning;
// Compute standard deviation
deviationRuntime = sqrt(stdSum/nRunning-averageRuntime*averageRuntime);
// Print results
printf("(Average Elapsed time, Standard deviation) = %e usec %e usec\n", averageRuntime, deviationRuntime);
// Print sum from assembly loop
printf("Sum = %llu\n", sum);
For example, with nLoop < 2^32, I get correct values for diff, avgSum and stdSum. Indeed, the printf ,with nLoop = 4.0e+9, gives :
sizeof(unsigned long long int) = 8
sizeof(unsigned long int) = 4
diff = 9.617167e+06
avgSum = 9.617167e+06
diff = 9.499878e+06
avgSum = 1.911704e+07
(Average Elapsed time, Standard deviation) = 9.558522e+06 usec 5.864450e+04 usec
Sum = 4000000000
The code is compiled on Debian Sparc 32 bits Etch with gcc 4.1.2.
Unfortunately, if I take for example nLoop = 5.0e+9, I get small and incorrect values for measured times; here's the printf output in this case :
sizeof(unsigned long long int) = 8
sizeof(unsigned long int) = 4
diff = 5.800000e+01
avgSum = 5.800000e+01
diff = 4.000000e+00
avgSum = 6.200000e+01
(Average Elapsed time, Standard deviation) = 3.100000e+01 usec 2.700000e+01 usec
Sum = 5000000000
I don't know where the issue could come from, I have done other tests using uint64_t but without success.
Maybe the problem is that I handle large integers (> 2^32) with 32 bits OS or it may be the assembly inline code which doesn't support 8 bytes integer.
Update 1
Following the advice of @AndrewHenle, I took the same code but instead of inline Sparc Assembly snippet, I have just put a simple loop.
Here's the program with the simple loop which has got nLoop = 5.0e+9 (see the line "unsigned long long int nLoop = 5000000000ULL;", so above the limit 2^32-1 :
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <unistd.h>
#include <math.h>
#include <stdint.h>
int main (int argc, char *argv[])
{
// For indices of nRunning
int i;
// For indices of nRunning
unsigned long long int j;
// Set the number of executions
int nRunning = atoi(argv[1]);
// Set the sums
unsigned long long int avgSum = 0;
unsigned long long int stdSum = 0;
// Average of execution time
double averageRuntime = 0.0;
// Standard deviation of execution time
double deviationRuntime = 0.0;
// Init sum
unsigned long long int sum;
// Number of iterations
unsigned long long int nLoop = 5000000000ULL;
// DEBUG
printf("sizeof(unsigned long long int) = %zu\n",sizeof(unsigned long long int));
printf("sizeof(unsigned long int) = %zu\n",sizeof(unsigned long int));
// Time intervals
struct timeval tv1, tv2;
unsigned long long int diff;
// Loop for multiple executions
for (i=0; i<nRunning; i++)
{
// Reset sum
sum = 0;
// Start time
gettimeofday (&tv1, NULL);
// Loop with Sparc assembly into C source
/* asm volatile ("clr %%g1\n\t"
"clr %%g2\n\t"
"mov %1, %%g1\n" // %1 = input parameter
"loop:\n\t"
"add %%g2, 1, %%g2\n\t"
"subcc %%g1, 1, %%g1\n\t"
"bne loop\n\t"
"nop\n\t"
"mov %%g2, %0\n" // %0 = output parameter
: "=r" (sum) // output
: "r" (nLoop) // input
: "g1", "g2"); // clobbers
*/
// Classic loop
for (j=0; j<nLoop; j++)
sum ++;
// End time
gettimeofday (&tv2, NULL);
// Compute runtime for loop
diff = (unsigned long long int) ((tv2.tv_sec - tv1.tv_sec) * 1000000 + (tv2.tv_usec - tv1.tv_usec));
// Summing diff time
avgSum += diff;
stdSum += (diff*diff);
// DEBUG
printf("diff = %llu\n", diff);
printf("avgSum = %llu\n", avgSum);
printf("stdSum = %llu\n", stdSum);
// Print sum from assembly loop
printf("Sum = %llu\n", sum);
}
// Compute final averageRuntime
averageRuntime = avgSum/nRunning;
// Compute standard deviation
deviationRuntime = sqrt(stdSum/nRunning-averageRuntime*averageRuntime);
// Print results
printf("(Average Elapsed time, Standard deviation) = %e usec %e usec\n", averageRuntime, deviationRuntime);
return 0;
}
This code snippet is working fine, i.e the variable sum is printed as (see "printf("Sum = %llu\n", sum)") :
Sum = 5000000000
So the problem comes from the version with Sparc Assembly block.
I suspect, in this assembly code, the line "mov %1, %%g1\n" // %1 = input parameter to badly store nLoop into %g1 register (I think that %g1 is a 32 bits register, so can't store values above 2^32-1).
However, the output parameter (variable sum) at the line :
"mov %%g2, %0\n" // %0 = output parameter
is above the limit since it is equal to 5000000000.
I attach the vimdiff between the version with Assembly loop and without it :
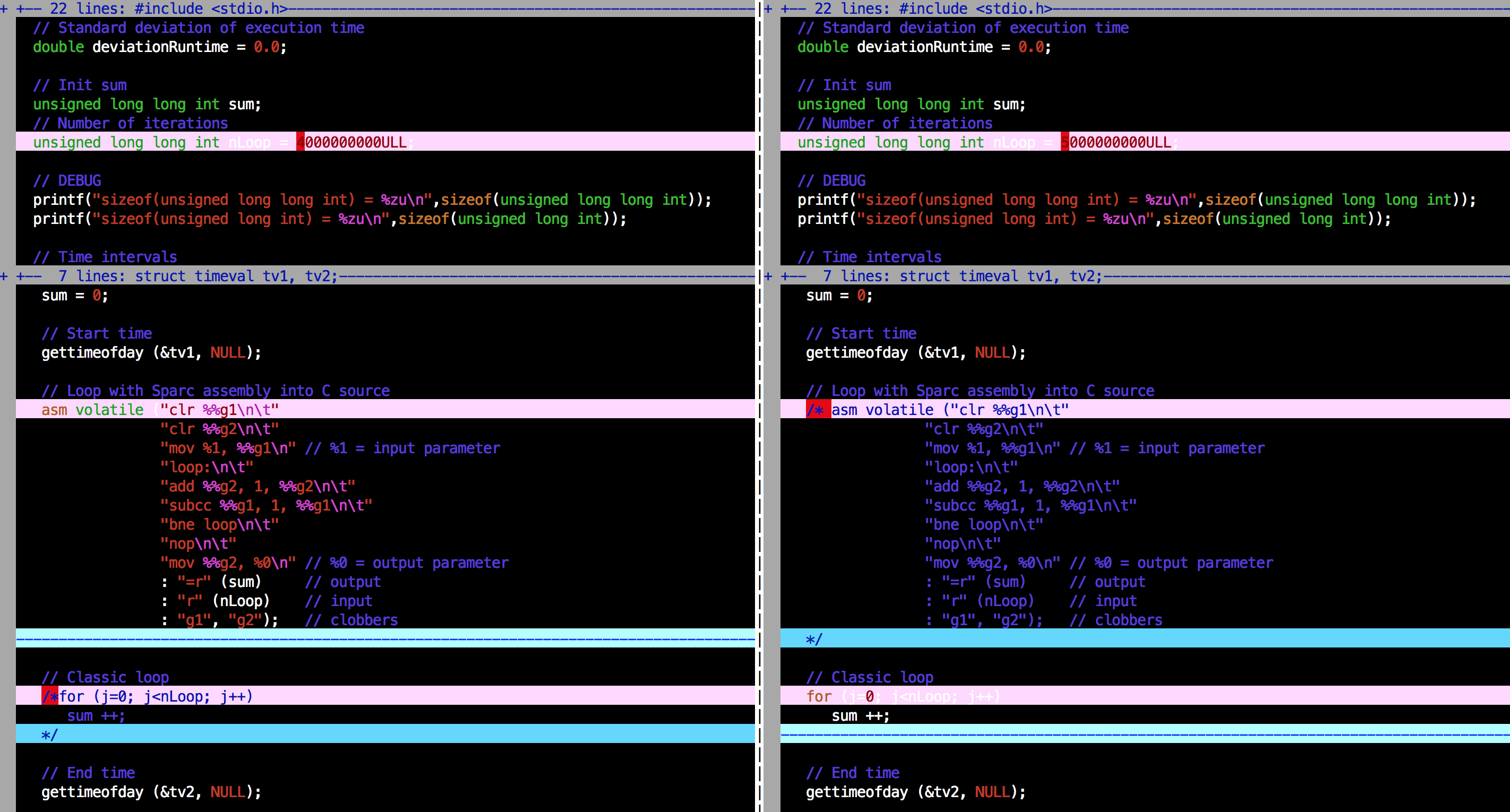
On the left, program With Assembly, on the right, Without Assembly (just a simple loop instead
I remind you my issue is that, for nLoop > 2^32-1 and with Assembly loop, I get a valid sum parameter at the end of execution but not valid (too short) average and standard deviation times (spent into loop); here's an example of output with nLoop = 5000000000ULL :
sizeof(unsigned long long int) = 8
sizeof(unsigned long int) = 4
diff = 17
avgSum = 17
stdSum = 289
Sum = 5000000000
diff = 4
avgSum = 21
stdSum = 305
Sum = 5000000000
(Average Elapsed time, Standard deviation) = 1.000000e+01 usec 7.211103e+00 usec
With taking nLoop = 4.0e+9, i.e nLoop = 4000000000ULL, there is no problem, the times values are valid.
Update 2
I am searching more deeply by generating Assembly code. The version with nLoop = 4000000000 (4.0e+9) is below :
.file "loop-WITH-asm-inline-4-Billions.c"
.section ".rodata"
.align 8
.LLC1:
.asciz "sizeof(unsigned long long int) = %zu\n"
.align 8
.LLC2:
.asciz "sizeof(unsigned long int) = %zu\n"
.align 8
.LLC3:
.asciz "diff = %llu\n"
.align 8
.LLC4:
.asciz "avgSum = %llu\n"
.align 8
.LLC5:
.asciz "stdSum = %llu\n"
.align 8
.LLC6:
.asciz "Sum = %llu\n"
.global __udivdi3
.global __cmpdi2
.global __floatdidf
.align 8
.LLC7:
.asciz "(Average Elapsed time, Standard deviation) = %e usec %e usec\n"
.align 8
.LLC0:
.long 0
.long 0
.section ".text"
.align 4
.global main
.type main, #function
.proc 04
main:
save %sp, -248, %sp
st %i0, [%fp+68]
st %i1, [%fp+72]
ld [%fp+72], %g1
add %g1, 4, %g1
ld [%g1], %g1
mov %g1, %o0
call atoi, 0
nop
mov %o0, %g1
st %g1, [%fp-68]
st %g0, [%fp-64]
st %g0, [%fp-60]
st %g0, [%fp-56]
st %g0, [%fp-52]
sethi %hi(.LLC0), %g1
or %g1, %lo(.LLC0), %g1
ldd [%g1], %f8
std %f8, [%fp-48]
sethi %hi(.LLC0), %g1
or %g1, %lo(.LLC0), %g1
ldd [%g1], %f8
std %f8, [%fp-40]
mov 0, %g2
sethi %hi(4000000000), %g3
std %g2, [%fp-24]
sethi %hi(.LLC1), %g1
or %g1, %lo(.LLC1), %o0
mov 8, %o1
call printf, 0
nop
sethi %hi(.LLC2), %g1
or %g1, %lo(.LLC2), %o0
mov 4, %o1
call printf, 0
nop
st %g0, [%fp-84]
b .LL2
nop
.LL3:
st %g0, [%fp-32]
st %g0, [%fp-28]
add %fp, -92, %g1
mov %g1, %o0
mov 0, %o1
call gettimeofday, 0
nop
ldd [%fp-24], %o4
clr %g1
clr %g2
mov %o4, %g1
loop:
add %g2, 1, %g2
subcc %g1, 1, %g1
bne loop
nop
mov %g2, %o4
std %o4, [%fp-32]
add %fp, -100, %g1
mov %g1, %o0
mov 0, %o1
call gettimeofday, 0
nop
ld [%fp-100], %g2
ld [%fp-92], %g1
sub %g2, %g1, %g2
sethi %hi(999424), %g1
or %g1, 576, %g1
smul %g2, %g1, %g3
ld [%fp-96], %g2
ld [%fp-88], %g1
sub %g2, %g1, %g1
add %g3, %g1, %g1
st %g1, [%fp-12]
sra %g1, 31, %g1
st %g1, [%fp-16]
ldd [%fp-64], %o4
ldd [%fp-16], %g2
addcc %o5, %g3, %g3
addx %o4, %g2, %g2
std %g2, [%fp-64]
ld [%fp-16], %g2
ld [%fp-12], %g1
smul %g2, %g1, %g4
ld [%fp-16], %g2
ld [%fp-12], %g1
smul %g2, %g1, %g1
add %g4, %g1, %g4
ld [%fp-12], %g2
ld [%fp-12], %g1
umul %g2, %g1, %g3
rd %y, %g2
add %g4, %g2, %g4
mov %g4, %g2
ldd [%fp-56], %o4
addcc %o5, %g3, %g3
addx %o4, %g2, %g2
std %g2, [%fp-56]
sethi %hi(.LLC3), %g1
or %g1, %lo(.LLC3), %o0
ld [%fp-16], %o1
ld [%fp-12], %o2
call printf, 0
nop
sethi %hi(.LLC4), %g1
or %g1, %lo(.LLC4), %o0
ld [%fp-64], %o1
ld [%fp-60], %o2
call printf, 0
nop
sethi %hi(.LLC5), %g1
or %g1, %lo(.LLC5), %o0
ld [%fp-56], %o1
ld [%fp-52], %o2
call printf, 0
nop
sethi %hi(.LLC6), %g1
or %g1, %lo(.LLC6), %o0
ld [%fp-32], %o1
ld [%fp-28], %o2
call printf, 0
nop
ld [%fp-84], %g1
add %g1, 1, %g1
st %g1, [%fp-84]
.LL2:
ld [%fp-84], %g2
ld [%fp-68], %g1
cmp %g2, %g1
bl .LL3
nop
ld [%fp-68], %g1
sra %g1, 31, %g1
ld [%fp-68], %g3
mov %g1, %g2
ldd [%fp-64], %o0
mov %g2, %o2
mov %g3, %o3
call __udivdi3, 0
nop
mov %o0, %g2
mov %o1, %g3
std %g2, [%fp-136]
ldd [%fp-136], %o0
mov 0, %o2
mov 0, %o3
call __cmpdi2, 0
nop
mov %o0, %g1
cmp %g1, 1
bl .LL6
nop
ldd [%fp-136], %o0
call __floatdidf, 0
nop
std %f0, [%fp-144]
b .LL5
nop
.LL6:
ldd [%fp-136], %o4
and %o4, 0, %g2
and %o5, 1, %g3
ld [%fp-136], %o5
sll %o5, 31, %g1
ld [%fp-132], %g4
srl %g4, 1, %o5
or %o5, %g1, %o5
ld [%fp-136], %g1
srl %g1, 1, %o4
or %g2, %o4, %g2
or %g3, %o5, %g3
mov %g2, %o0
mov %g3, %o1
call __floatdidf, 0
nop
std %f0, [%fp-144]
ldd [%fp-144], %f8
ldd [%fp-144], %f10
faddd %f8, %f10, %f8
std %f8, [%fp-144]
.LL5:
ldd [%fp-144], %f8
std %f8, [%fp-48]
ld [%fp-68], %g1
sra %g1, 31, %g1
ld [%fp-68], %g3
mov %g1, %g2
ldd [%fp-56], %o0
mov %g2, %o2
mov %g3, %o3
call __udivdi3, 0
nop
mov %o0, %g2
mov %o1, %g3
std %g2, [%fp-128]
ldd [%fp-128], %o0
mov 0, %o2
mov 0, %o3
call __cmpdi2, 0
nop
mov %o0, %g1
cmp %g1, 1
bl .LL8
nop
ldd [%fp-128], %o0
call __floatdidf, 0
nop
std %f0, [%fp-120]
b .LL7
nop
.LL8:
ldd [%fp-128], %o4
and %o4, 0, %g2
and %o5, 1, %g3
ld [%fp-128], %o5
sll %o5, 31, %g1
ld [%fp-124], %g4
srl %g4, 1, %o5
or %o5, %g1, %o5
ld [%fp-128], %g1
srl %g1, 1, %o4
or %g2, %o4, %g2
or %g3, %o5, %g3
mov %g2, %o0
mov %g3, %o1
call __floatdidf, 0
nop
std %f0, [%fp-120]
ldd [%fp-120], %f8
ldd [%fp-120], %f10
faddd %f8, %f10, %f8
std %f8, [%fp-120]
.LL7:
ldd [%fp-48], %f8
ldd [%fp-48], %f10
fmuld %f8, %f10, %f8
ldd [%fp-120], %f10
fsubd %f10, %f8, %f8
std %f8, [%fp-112]
ldd [%fp-112], %f8
fsqrtd %f8, %f8
std %f8, [%fp-152]
ldd [%fp-152], %f10
ldd [%fp-152], %f8
fcmpd %f10, %f8
nop
fbe .LL9
nop
ldd [%fp-112], %o0
call sqrt, 0
nop
std %f0, [%fp-152]
.LL9:
ldd [%fp-152], %f8
std %f8, [%fp-40]
sethi %hi(.LLC7), %g1
or %g1, %lo(.LLC7), %o0
ld [%fp-48], %o1
ld [%fp-44], %o2
ld [%fp-40], %o3
ld [%fp-36], %o4
call printf, 0
nop
mov 0, %g1
mov %g1, %i0
restore
jmp %o7+8
nop
.size main, .-main
.ident "GCC: (GNU) 4.1.2 20061115 (prerelease) (Debian 4.1.1-21)"
.section ".note.GNU-stack"
When I generate the Assembly code version with nLoop = 5000000000 (5.0e+9), the differences are illustrated on the following figure (with vimdiff) :
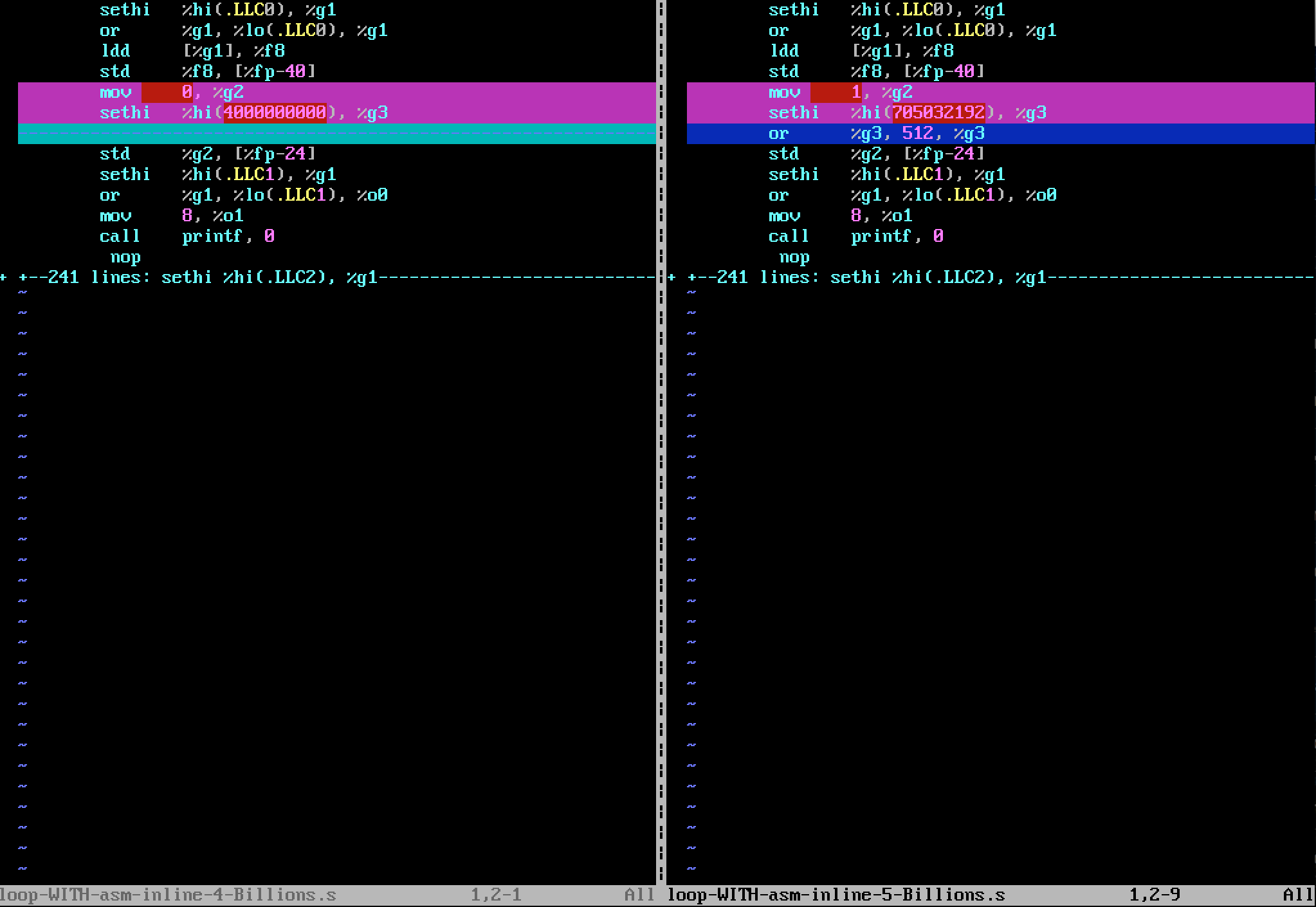
the block of "4 Billions" version :
mov 0, %g2
sethi %hi(4000000000), %g3
is replaced in "5 Billions" version by :
mov 1, %g2
sethi %hi(705032192), %g3
or %g3, 512, %g3
I can see that 5.0+e9 can't be coded on 32 bits, since the instruction
sethi %hi(705032192), %g3
Paradoxically, when I compile the version "5 Billions" Assembly code, the ouput parameter sum is computed well, i.e is equal to 5 Billions, and I can't explain it.
sumin your assembler code which isunsigned long long. Of course you have to adapt your asm code to match the size and type of your parameters. Did you try to use C code and let the compiler to the work? If the compiler supports 8 byte integer values it can create code to manipulate them. – Boscagesumis computed well (=4.0e+9 for first example and 5.0e+9 for second one). In both cases,sumis declared asunsigned long long int. I don't understand why this is not the same case with usingnLoop > 2^32in assembly input parameter ? – Decommission"add %%g2, 1, %%g2\n\t"seems to do it because output parameter (sum) at the end of assembly code gives values over 2^32 (4.0e+9 with valid times and 5.0e+9 with incorrect times). – Decommissiontv1andtv2and verify the range of the difference. – Boscageint nRunning = ...; printf("avgSum = %e\n", avgSum); averageRuntime = avgSum/nRunning; printf("(Average Elapsed time, Standard deviation) = %e usec ...\n", averageRuntime, ...);and output9.617167e+06, 9.558522e+06. This makes no sense. Is this true code and true output? Else, I think you have memory corruption due toasm(). – AvonnRunning=2at the execution (./a.out 2), this is the argument of executable.9.558522e+06is the average of these 2 executions and5.864450e+04the standard deviation. – Decommissionmovon SPARC is a synthetic instruction that's actually implemented as one or more other instructions, see docs.oracle.com/cd/E19120-01/open.solaris/816-1681/…. I'd recommend getting it working without hand-jammed ASM code first. – Poem