I am storing message sequences in the database each sequence can have up to N number of messages. I want to create a hash function which will represent the message sequence and enable to check faster if message sequence exists.
Each message has a case-sensitive alphanumeric universal unique id (UUID).
Consider following messages (M1, M2, M3) with ids-
M1 - a3RA0000000e0taBB
M2 - a3RA00033000e0taC
M3 - a3RA0787600e0taBB
Message sequences can be
Sequence-1 : (M1,M2,M3)
Sequence-2 : (M1,M3,M2)
Sequence-3 : (M2,M1,M3)
Sequence-4 : (M1,M2)
Sequence-5 : (M2,M3)
...etc...
Following is the database structure example for storing message sequence
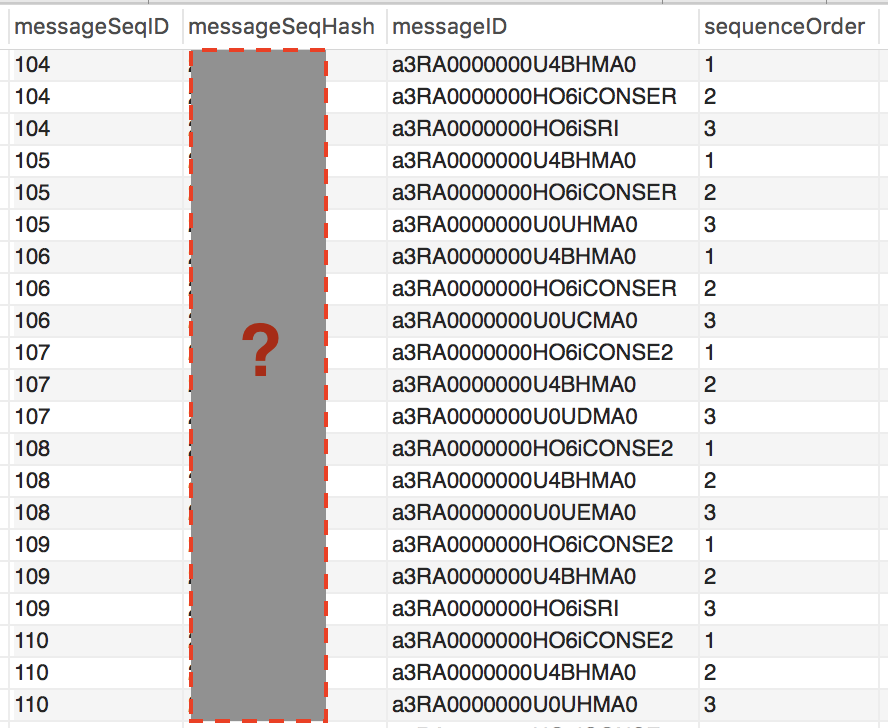
Given the message sequence, we need to check whether that message sequence exists in the database. For example, check if message sequence M1 -> M2 -> M3 i.e. with UIDs (a3RA0000000e0taBB -> a3RA00033000e0taC -> a3RA0787600e0taBB) exists in the database.
Instead of scanning the rows in the table, I want to create a hash function which represents the message sequence with a hash value. Using the hash value lookup in the table supposedly faster.
My simple hash function is-
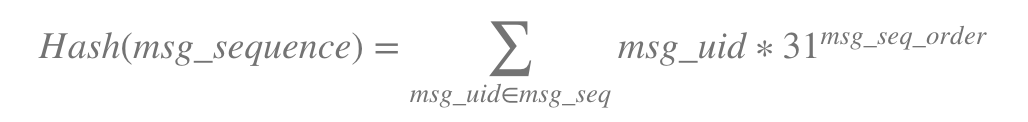
I am wondering what would be an optimal hash function for storing the message sequence hash for faster is exists check.