This should be an interresting challenge. I'm looking for an algorithm that doesn't exist yet (to the best of my knowledge)
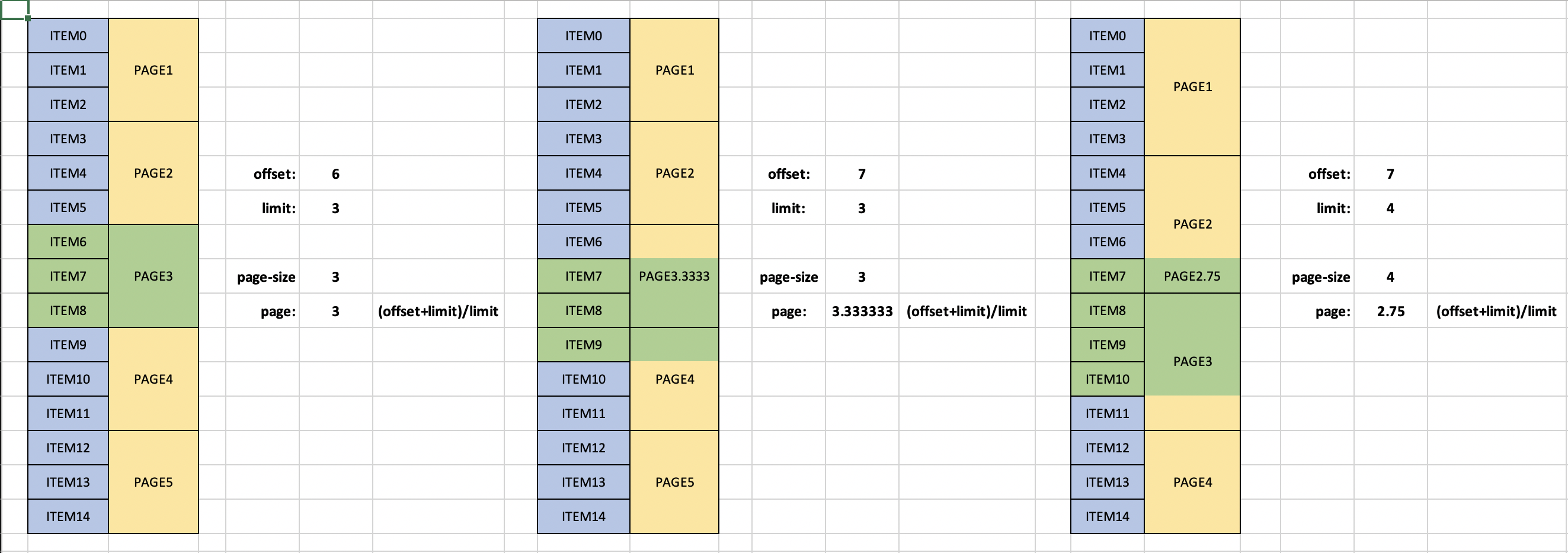
- We have a database accessing function that can read pages of records at a time, using a page-number and page-size as arguments. Lets call this function
getFromDatabase(int page, int size). - We want to offer a REST API which should return records based on an offset and limit. Lets wrap this in a function
getRecords(int offset, int limit).
Somehow we must use the given offset and limit to retrieve the matching database records which can only be access by page and size. Obviously, offset/limit won't always map to a single page/size. The challenge is finding an algorihm that makes the "ideal" number of getFromDatabase calls to retrieve all records. This algorithm should take several factors into account:
- Each call to
getFromDatabasehas a certain overhead cost; keep calls to a minimum. - Each record retrieved adds additonal overhead; retrieve as few records as possible (it's okay to retrieve "waste" if it decreases total overhead).
- The algorithm itself has overhead costs as well; obviously they should not outweight any benefits.
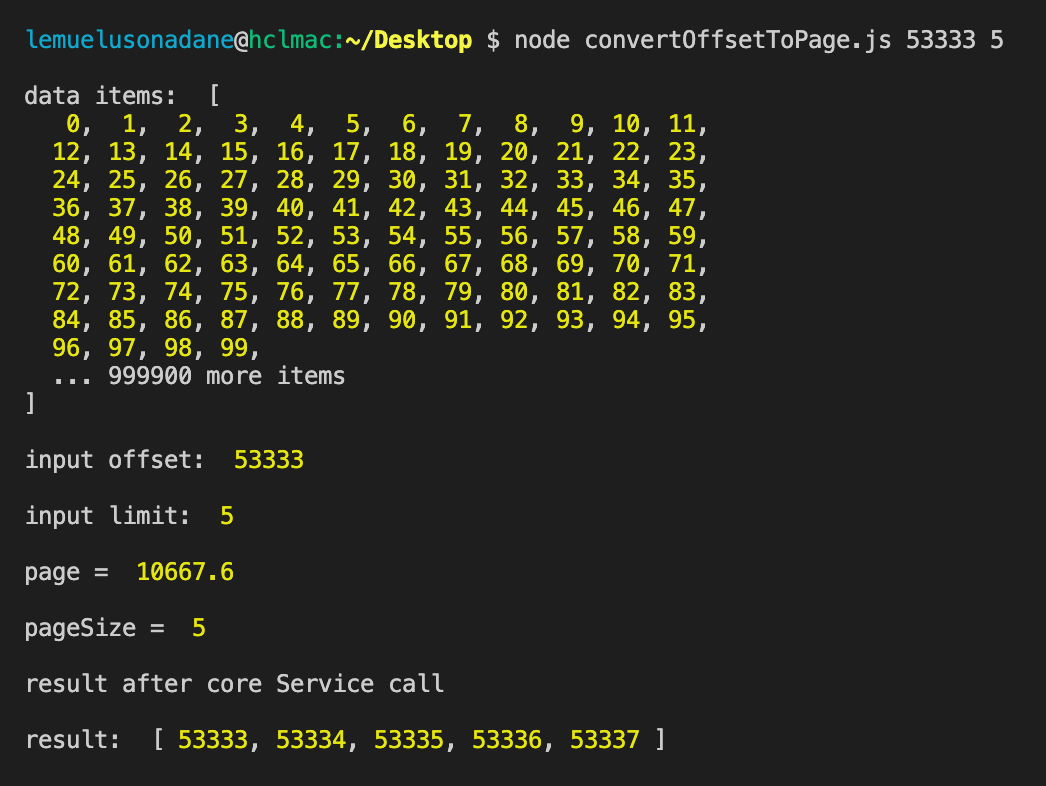
I've come up with the following algorithm: http://jsfiddle.net/mwvdlee/A7J9C/ (JS code, but the algorithm is language-agnostic). Essentially it is the following pseudocode:
do {
do {
try to convert (offset,limit) to (page,size)
if too much waste
lower limit by some amount
else
call `getDatabaseRecords()`
filter out waste records
increase offset to first record not yet retrieved
lower limit to last records not yet retrieved
} until some records were retrieved
} until all records are retrieved from database
The key of this algorithm is in determining too much waste and some amount. But this algorithm isn't optimal, nor is it guarenteed to be complete (it may well be, I just can't proof it).
Are there any better (known?) algorithms, or improvements I could make? Does anybody have good ideas of how to tackle this problem?
limit1? – DecreasinggetFromDatabase(page: 2, size: 20)and get all data in a single call (and discard some rows)? This sounds not too hard to solve so I might have missed some requirement. It is always possible to construct a single call that wastes at most 50%. – PalefacegetFromDatabase(page: 0, size: 190), but then you'd get 73 records you won't need. IfgetFromDatabasedoes all kinds of complex stuff with those 73 records, that may be a lot of wasted time. It would have been faster to get page 1, size 73 and page 3, size 48, which have just 4 waste records in total. The problem is how to quickly determine which pages/sizes combinations have the least total overhead costs. – Decreasing{O:73,L:117}earlier, based on maximum 10% waste. for a 2% waste it returns 3 pages. However, the method uses brute force, so it's slow. – Decreasing