I am attempting to implement multiprocessing in Python (Windows Server 2012) and am having trouble achieving the degree of performance improvement that I expect. In particular, for a set of tasks which are almost entirely independent, I would expect a linear improvement with additional cores.
I understand that--especially on Windows--there is overhead involved in opening new processes [1], and that many quirks of the underlying code can get in the way of a clean trend. But in theory the trend should ultimately still be close to linear for a fully parallelized task [2]; or perhaps logistic if I were dealing with a partially serial task [3].
However, when I run multiprocessing.Pool on a prime-checking test function (code below), I get a nearly perfect square-root relationship up to N_cores=36 (the number of physical cores on my server) before the expected performance hit when I get into the additional logical cores.
Here is a plot of my performance test results :
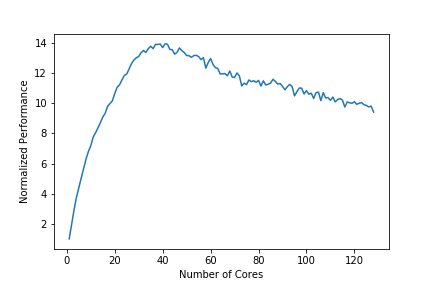
( "Normalized Performance" is [ a run time with 1 CPU-core ] divided by [ a run time with N CPU-cores ] ).
Is it normal to have this dramatic diminishing of returns with multiprocessing? Or am I missing something with my implementation?
import numpy as np
from multiprocessing import Pool, cpu_count, Manager
import math as m
from functools import partial
from time import time
def check_prime(num):
#Assert positive integer value
if num!=m.floor(num) or num<1:
print("Input must be a positive integer")
return None
#Check divisibility for all possible factors
prime = True
for i in range(2,num):
if num%i==0: prime=False
return prime
def cp_worker(num, L):
prime = check_prime(num)
L.append((num, prime))
def mp_primes(omag, mp=cpu_count()):
with Manager() as manager:
np.random.seed(0)
numlist = np.random.randint(10**omag, 10**(omag+1), 100)
L = manager.list()
cp_worker_ptl = partial(cp_worker, L=L)
try:
pool = Pool(processes=mp)
list(pool.imap(cp_worker_ptl, numlist))
except Exception as e:
print(e)
finally:
pool.close() # no more tasks
pool.join()
return L
if __name__ == '__main__':
rt = []
for i in range(cpu_count()):
t0 = time()
mp_result = mp_primes(6, mp=i+1)
t1 = time()
rt.append(t1-t0)
print("Using %i core(s), run time is %.2fs" % (i+1, rt[-1]))
Note: I am aware that for this task it would likely be more efficient to implement multithreading, but the actual script for which this one is a simplified analog is incompatible with Python multithreading due to GIL.

tqdm? – Succoth__doc__of imap, that it can be much slower than map? – Succothmultiprocessingdocs should explain what they are doing better. A Manager holds Python objects and allows other processes to manipulate them using proxies - meaning it is synching the list to all workers. You'd be much better off with amultiprocessing.Arrayand give each work item the index where the result should be placed. Also,mapis better thanlist(imap)and likelychunksize=1will help. – Ephedrineos.cpu_count()may be incorrect. In Python 3 it's callingGetMaximumProcessorCount(equivalent to POSIX_SC_NPROCESSORS_CONF) instead ofGetActiveProcessorCount(equivalent to POSIX_SC_NPROCESSORS_ONLN). For systems that support hot-plugging CPUs, this count could be much larger than the number of actually available cores. – Blackandwhiteos.cpu_count()bug may report the max available if both groups were completely full, i.e. 128 cores. – Blackandwhiteos.cpu_count. If the system has 72 logical cores, the CPU count should be 72, not 128. – Blackandwhite