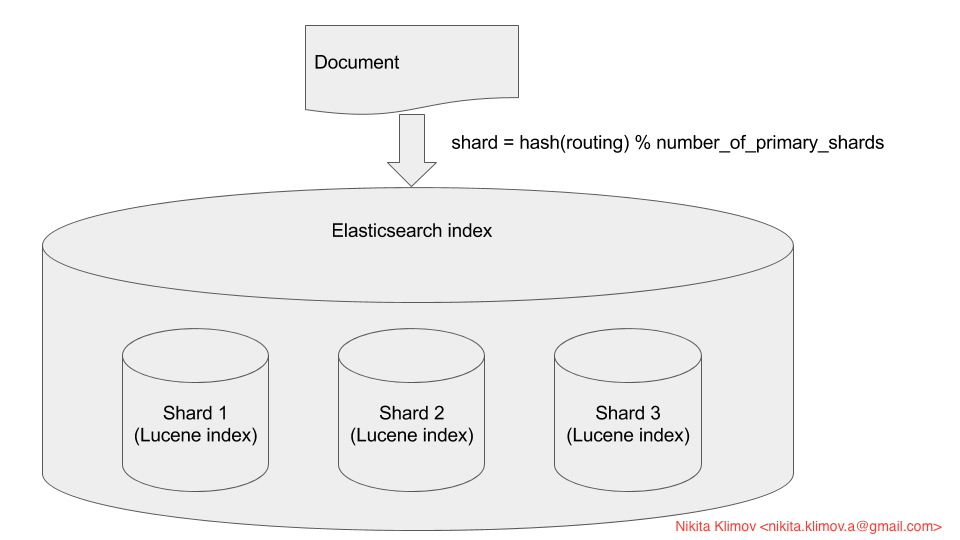
I am trying to figure out the concept of elastic search index and quite don't understand it. I want to make a couple of points in advance. I understand how inverse document index works (mapping terms to document ids), I also understand how the document ranking works based on TF-IDF. What I don't understand is the data structure of the actual index. When referring to the elastic search documentation it describes the index as a "table with mappings to the documents". So, here comes sharding!! When you look at typical picture of the elastic search index, it is represented like this:
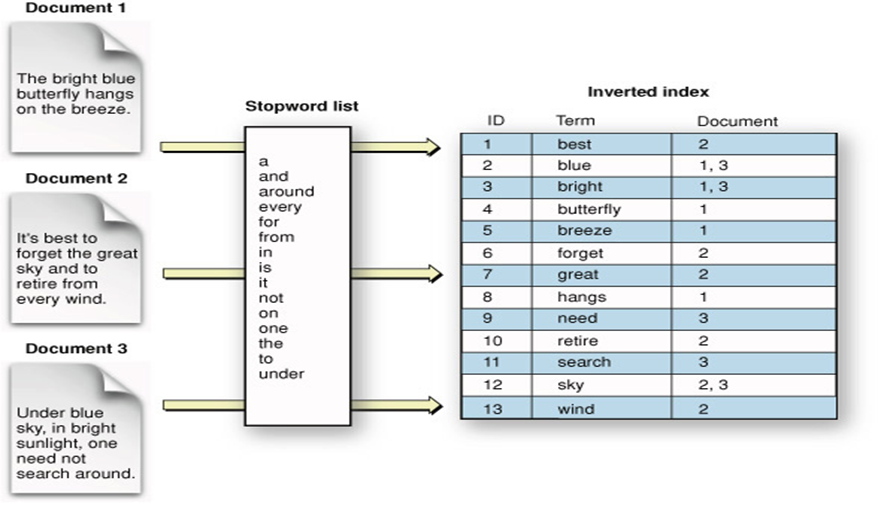 What the picture doesn't show is how the actual partitioning happens and how this [table -> document] link is split across multiple shards. For instance, does each shard split the table vertically? Meaning the inverted index table only contains terms that are present on the shard. For instance, lets assume we have 3 shards, meaning the first one will contain document1, the second shard only contains document 2 and the 3rd shard is document 3. Now, would the first shard index only contain terms that are present in document1? In this case [Blue, bright, butterfly, breeze, hangs]. If so, what if someone searches for [forget], how does elastic search "knows" not to search in shard 1, or it searches all shards every time?
When you look at the cluster image:
What the picture doesn't show is how the actual partitioning happens and how this [table -> document] link is split across multiple shards. For instance, does each shard split the table vertically? Meaning the inverted index table only contains terms that are present on the shard. For instance, lets assume we have 3 shards, meaning the first one will contain document1, the second shard only contains document 2 and the 3rd shard is document 3. Now, would the first shard index only contain terms that are present in document1? In this case [Blue, bright, butterfly, breeze, hangs]. If so, what if someone searches for [forget], how does elastic search "knows" not to search in shard 1, or it searches all shards every time?
When you look at the cluster image:
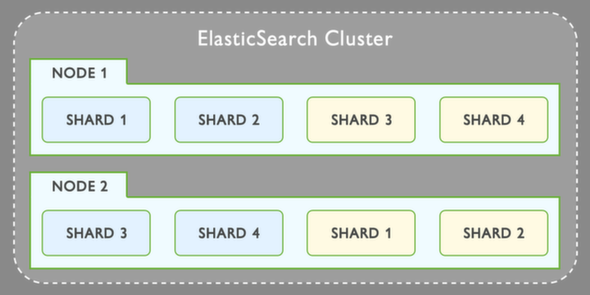
It is not clear what exactly is in shard1, shard2 and shard3. We go from Term -> DocumentId -> Document to a "rectangular" shard, but what does the shard contain exactly?
I would appreciate if someone can explain it from the picture above.