I'm trying to convert a convolution layer to a fully-connected layer.
For example, there is an example of 3×3 input and 2x2 kernel:

which is equivalent to a vector-matrix multiplication,
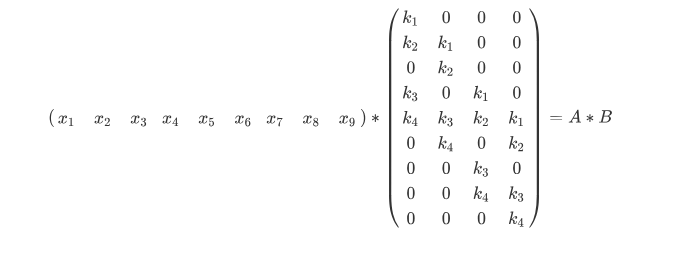
Is there a function in PyTorch to get the matrix B?
I'm trying to convert a convolution layer to a fully-connected layer.
For example, there is an example of 3×3 input and 2x2 kernel:
which is equivalent to a vector-matrix multiplication,
Is there a function in PyTorch to get the matrix B?
I can only partially answer your question:
In your example above, you write the kernel as matrix and the input as a vector. If you are fine with writing the input as a matrix, you can use torch.nn.Unfold which explicitly calculates a convolution in the documentation:
# Convolution is equivalent with Unfold + Matrix Multiplication + Fold (or view to output shape)
inp = torch.randn(1, 3, 10, 12)
w = torch.randn(2, 3, 4, 5)
inp_unf = torch.nn.functional.unfold(inp, (4, 5))
out_unf = inp_unf.transpose(1, 2).matmul(w.view(w.size(0), -1).t()).transpose(1, 2)
out = out_unf.view(1, 2, 7, 8)
(torch.nn.functional.conv2d(inp, w) - out).abs().max()
# tensor(1.9073e-06)
If, however, you need to calculate the matrix for the kernel (the smaller matrix) you can use this function, which is based on Warren Weckessers answer:
def toeplitz_1_ch(kernel, input_size):
# shapes
k_h, k_w = kernel.shape
i_h, i_w = input_size
o_h, o_w = i_h-k_h+1, i_w-k_w+1
# construct 1d conv toeplitz matrices for each row of the kernel
toeplitz = []
for r in range(k_h):
toeplitz.append(linalg.toeplitz(c=(kernel[r,0], *np.zeros(i_w-k_w)), r=(*kernel[r], *np.zeros(i_w-k_w))) )
# construct toeplitz matrix of toeplitz matrices (just for padding=0)
h_blocks, w_blocks = o_h, i_h
h_block, w_block = toeplitz[0].shape
W_conv = np.zeros((h_blocks, h_block, w_blocks, w_block))
for i, B in enumerate(toeplitz):
for j in range(o_h):
W_conv[j, :, i+j, :] = B
W_conv.shape = (h_blocks*h_block, w_blocks*w_block)
return W_conv
which is not in pytorch but in numpy. This is for padding = 0 but can easily be adjusted by changing h_blocks and w_blocks and W_conv[i+j, :, j, :].
Update: Multiple output channels are just multiple of these matrices, as each output has its own kernel. Multiple input channels also have their own kernels - and their own matrices - over which you average after the convolution. This can be implemented as follows:
def conv2d_toeplitz(kernel, input):
"""Compute 2d convolution over multiple channels via toeplitz matrix
Args:
kernel: shape=(n_out, n_in, H_k, W_k)
input: shape=(n_in, H_i, W_i)"""
kernel_size = kernel.shape
input_size = input.shape
output_size = (kernel_size[0], input_size[1] - (kernel_size[1]-1), input_size[2] - (kernel_size[2]-1))
output = np.zeros(output_size)
for i,ks in enumerate(kernel): # loop over output channel
for j,k in enumerate(ks): # loop over input channel
T_k = toeplitz_1_ch(k, input_size[1:])
output[i] += T_k.dot(input[j].flatten()).reshape(output_size[1:]) # sum over input channels
return output
To check the correctness:
k = np.random.randn(4*3*3*3).reshape((4,3,3,3))
i = np.random.randn(3,7,9)
out = conv2d_toeplitz(k, i)
# check correctness of convolution via toeplitz matrix
print(np.sum((out - F.conv2d(torch.tensor(i).view(1,3,7,9), torch.tensor(k)).numpy())**2))
>>> 1.0063523219807736e-28
Update 2:
It is also possible to do this without looping in one matrix:
def toeplitz_mult_ch(kernel, input_size):
"""Compute toeplitz matrix for 2d conv with multiple in and out channels.
Args:
kernel: shape=(n_out, n_in, H_k, W_k)
input_size: (n_in, H_i, W_i)"""
kernel_size = kernel.shape
output_size = (kernel_size[0], input_size[1] - (kernel_size[1]-1), input_size[2] - (kernel_size[2]-1))
T = np.zeros((output_size[0], int(np.prod(output_size[1:])), input_size[0], int(np.prod(input_size[1:]))))
for i,ks in enumerate(kernel): # loop over output channel
for j,k in enumerate(ks): # loop over input channel
T_k = toeplitz_1_ch(k, input_size[1:])
T[i, :, j, :] = T_k
T.shape = (np.prod(output_size), np.prod(input_size))
return T
The input has to be flattened and the output reshaped after multiplication.
Checking for correctness (using the same i and k as above):
T = toeplitz_mult_ch(k, i.shape)
out = T.dot(i.flatten()).reshape((1,4,5,7))
# check correctness of convolution via toeplitz matrix
print(np.sum((out - F.conv2d(torch.tensor(i).view(1,3,7,9), torch.tensor(k)).numpy())**2))
>>> 1.5486060830252635e-28
You can use my code for convolution with circular padding:
import numpy as np
import scipy.linalg as linalg
def toeplitz_1d(k, x_size):
k_size = k.size
r = *k[(k_size // 2):], *np.zeros(x_size - k_size), *k[:(k_size // 2)]
c = *np.flip(k)[(k_size // 2):], *np.zeros(x_size - k_size), *np.flip(k)[:(k_size // 2)]
t = linalg.toeplitz(c=c, r=r)
return t
def toeplitz_2d(k, x_size):
k_h, k_w = k.shape
i_h, i_w = x_size
ks = np.zeros((i_w, i_h * i_w))
for i in range(k_h):
ks[:, i*i_w:(i+1)*i_w] = toeplitz_1d(k[i], i_w)
ks = np.roll(ks, -i_w, 1)
t = np.zeros((i_h * i_w, i_h * i_w))
for i in range(i_h):
t[i*i_h:(i+1)*i_h,:] = ks
ks = np.roll(ks, i_w, 1)
return t
def toeplitz_3d(k, x_size):
k_oc, k_ic, k_h, k_w = k.shape
i_c, i_h, i_w = x_size
t = np.zeros((k_oc * i_h * i_w, i_c * i_h * i_w))
for o in range(k_oc):
for i in range(k_ic):
t[(o * (i_h * i_w)):((o+1) * (i_h * i_w)), (i * (i_h * i_w)):((i+1) * (i_h * i_w))] = toeplitz_2d(k[o, i], (i_h, i_w))
return t
if __name__ == "__main__":
import torch
k = np.random.randint(50, size=(3, 2, 3, 3))
x = np.random.randint(50, size=(2, 5, 5))
t = toeplitz_3d(k, x.shape)
y = t.dot(x.flatten()).reshape(3, 5, 5)
xx = torch.nn.functional.pad(torch.from_numpy(x.reshape(1, 2, 5, 5)), pad=(1, 1, 1, 1), mode='circular')
yy = torch.conv2d(xx, torch.from_numpy(k))
err = ((y - yy.numpy()) ** 2).sum()
print(err)
While the other answers are correct, there is a faster way. In your example, you give an input of size 3x3 with a kernel of size 2x2. And your resulting circulant matrix multiplied by the input image is 9x9x4 operations, or 324 in total. Here is a method that does this with 4 x 4 x 4, or 64 operations in total. We will use Pytorch, but this could be done in Numpy, as well.
Assume an image input of shape (batch, channels, height, width):
import torch
def get_kernel_inputs(image, kernel):
out = torch.empty(image.size()[0], 0, 1, kernel.size()[-2] * kernel.size()[-1])
for k in range(image.size()[-2] - kernel.size()[-2] + 1):
for l in range(image.size()[-1] - kernel.size()[-1] + 1):
out = torch.cat([out,image[:, :, k:k+kernel.size()[-2],l:l + kernel.size()[-1]].reshape(image.size()[0], -1, 1, kernel.size()[-1] * kernel.size()[-2])], dim=1)
return out
Now let's test to see what size out this gives:
img = torch.rand(1, 1, 3, 3)
kernel = torch.rand(2, 2)
kernelized_img = get_kernel_inputs(img, kernel)
print(kernelized_img.size())
This yields a size of:
torch.Size([1, 4, 1, 4])
So there are 16 values stored in the above tensor. Now let's matrix multiply:
print(torch.matmul(kernelized_img, kernel.view(4)))
This is 16 x 4 multiplications.
Finally, let's test that this is, in fact, giving out the correct value by using the Torch Conv2d module:
import torch.nn as nn
mm = nn.Conv2d(1, 1, (2,2), bias=False)
with torch.no_grad():
kernel_test = mm.weight
print("Control ", mm(img))
print("Test", torch.matmul(kernelized_img, kernel_test.view(4)).view(1, 1, 2, 2))
Control tensor([[[[-0.0089, 0.0178],
[-0.1419, 0.2720]]]], grad_fn=<ThnnConv2DBackward>)
Test tensor([[[[-0.0089, 0.0178],
[-0.1419, 0.2720]]]], grad_fn=<ViewBackward>)
All we are doing differently in the above is reshaping the image instead of the kernel.
Setting the image height and width equal and the kernel height and width equal, where
i=image height/width
k=kernel height/width
Then the difference in the number of calculations in the Toeplitz method vs. the above method is:
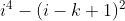
Edit Addition: The above implementation only worked on single-channel inputs. For this definition to work on multiple channel inputs and outputs, plus handle batches, can do the following:
def get_kernel_inputs(image, kernel):
out=torch.empty(image.size()[0], image.size()[1], 0, kernel.size()[-2]*kernel.size()[-1])
out_size=[image.size()[-2]-kernel.size()[-2]+1,(image.size()[-1]-kernel.size()[-1]+1)]
for k in range(out_size[0]):
for l in range(out_size[1]):
out=torch.cat([out,image[:,:,k:k+kernel.size()[-2],l:l+kernel.size()[-1]].reshape(image.size()[0],-1,1,kernel.size()[-1]*kernel.size()[-2])],dim=2)
preout=out.permute(0,2,1,3).reshape(image.size()[0],-1,image.size()[1]*kernel.size()[-2]*kernel.size()[-1])
kernel1 = kernel.view(kernel.size()[0], -1)
out = torch.matmul(preout, kernel1.T).permute(0, 2, 1).reshape(image.size()[0], kernel.size()[0],
out_size[0], out_size[1])
return out
images=torch.rand(5, 3, 32, 32)
mm=nn.Conv2d(3, 32, (3, 3), bias=False)
#Set the kernel to Conv2d init for testing
with torch.no_grad():
kernel=mm.weight
print(get_kernel_inputs(images, kernel))
print(mm(images))
© 2022 - 2024 — McMap. All rights reserved.