I am working on handprinted multi-digit recognition with Java, using OpenCV library for preprocessing and segmentation, and a Keras model trained on MNIST (with an accuracy of 0.98) for recognition.
The recognition seems to work quite well, apart from one thing. The network quite often fails to recognize the ones (number "one"). I can't figure out if it happens due to preprocessing / incorrect implementation of the segmentation, or if a network trained on standard MNIST just hasn't seen the number one which looks like my test cases.
Here's what the problematic digits look like after preprocessing and segmentation:
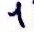 becomes
becomes  and is classified as
and is classified as 4.
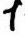 becomes
becomes  and is classified as
and is classified as 7.
 becomes
becomes  and is classified as
and is classified as 4.
And so on...
Is this something that could be fixed by improving the segmentation process? Or rather by enhancing the training set?
Edit: Enhancing the training set (data augmentation) would definitely help, which I am already testing, the question of correct preprocessing still remains.
My preprocessing consists of resizing, converting to grayscale, binarization, inversion, and dilation. Here's the code:
Mat resized = new Mat();
Imgproc.resize(image, resized, new Size(), 8, 8, Imgproc.INTER_CUBIC);
Mat grayscale = new Mat();
Imgproc.cvtColor(resized, grayscale, Imgproc.COLOR_BGR2GRAY);
Mat binImg = new Mat(grayscale.size(), CvType.CV_8U);
Imgproc.threshold(grayscale, binImg, 0, 255, Imgproc.THRESH_OTSU);
Mat inverted = new Mat();
Core.bitwise_not(binImg, inverted);
Mat dilated = new Mat(inverted.size(), CvType.CV_8U);
int dilation_size = 5;
Mat kernel = Imgproc.getStructuringElement(Imgproc.CV_SHAPE_CROSS, new Size(dilation_size, dilation_size));
Imgproc.dilate(inverted, dilated, kernel, new Point(-1,-1), 1);
The preprocessed image is then segmented into individual digits as following:
List<Mat> digits = new ArrayList<>();
List<MatOfPoint> contours = new ArrayList<>();
Imgproc.findContours(preprocessed.clone(), contours, new Mat(), Imgproc.RETR_EXTERNAL, Imgproc.CHAIN_APPROX_SIMPLE);
// code to sort contours
// code to check that contour is a valid char
List rects = new ArrayList<>();
for (MatOfPoint contour : contours) {
Rect boundingBox = Imgproc.boundingRect(contour);
Rect rectCrop = new Rect(boundingBox.x, boundingBox.y, boundingBox.width, boundingBox.height);
rects.add(rectCrop);
}
for (int i = 0; i < rects.size(); i++) {
Rect x = (Rect) rects.get(i);
Mat digit = new Mat(preprocessed, x);
int border = 50;
Mat result = digit.clone();
Core.copyMakeBorder(result, result, border, border, border, border, Core.BORDER_CONSTANT, new Scalar(0, 0, 0));
Imgproc.resize(result, result, new Size(28, 28));
digits.add(result);
}


