I'm playing with jmh and in the section about looping they said that
You might notice the larger the repetitions count, the lower the "perceived" cost of the operation being measured. Up to the point we do each addition with 1/20 ns, well beyond what hardware can actually do. This happens because the loop is heavily unrolled/pipelined, and the operation to be measured is hoisted from the loop. Morale: don't overuse loops, rely on JMH to get the measurement right.
I tried it myself
@Benchmark
@OperationsPerInvocation(1)
public int measurewrong_1() {
return reps(1);
}
@Benchmark
@OperationsPerInvocation(1000)
public int measurewrong_1000() {
return reps(1000);
}
and got the following result:
Benchmark Mode Cnt Score Error Units
MyBenchmark.measurewrong_1 avgt 15 2.425 ± 0.137 ns/op
MyBenchmark.measurewrong_1000 avgt 15 0.036 ± 0.001 ns/op
It indeed shows that the MyBenchmark.measurewrong_1000 is dramatically faster than MyBenchmark.measurewrong_1. But I cannot really understand the optimization JVM does to make this performance improvement.
What do they mean the loop is unrolled/pipelined?
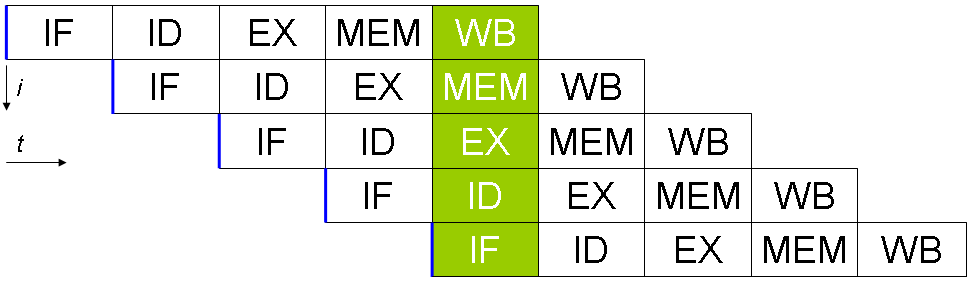
repsmethod do? – Acute