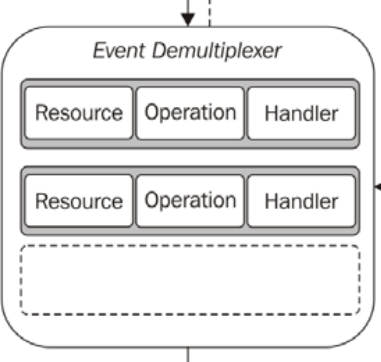
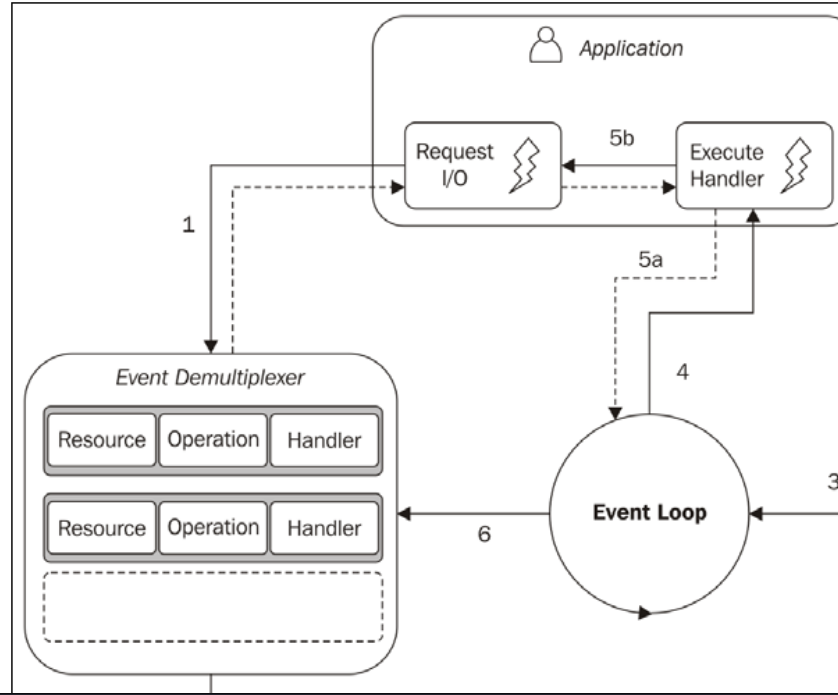
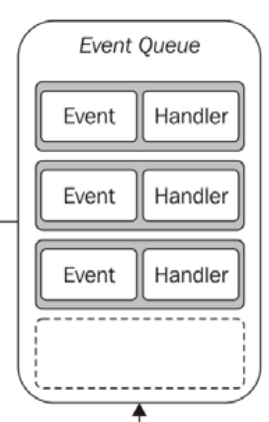
I'm not a Node programmer, but I'm interested in how the single-threaded non-blocking IO model works. After I read the article understanding-the-node-js-event-loop, I'm really confused about it. It gave an example for the model:
c.query(
'SELECT SLEEP(20);',
function (err, results, fields) {
if (err) {
throw err;
}
res.writeHead(200, {'Content-Type': 'text/html'});
res.end('<html><head><title>Hello</title></head><body><h1>Return from async DB query</h1></body></html>');
c.end();
}
);
Que: When there are two requests A(comes first) and B since there is only a single thread, the server-side program will handle the request A firstly: doing SQL querying is asleep statement standing for I/O wait. And The program is stuck at the I/O waiting, and cannot execute the code which renders the web page behind. Will the program switch to request B during the waiting? In my opinion, because of the single thread model, there is no way to switch one request from another. But the title of the example code says that everything runs in parallel except your code.
(P.S I'm not sure if I misunderstand the code or not since I have never used Node.)How Node switch A to B during the waiting? And can you explain the single-threaded non-blocking IO model of Node in a simple way? I would appreciate it if you could help me. :)