I'm having some fun trying to pick a decent SQL Server 2008 spatial index setup for a data set I am dealing with.
The dataset is polygons, representing contours over the whole globe. There are 106,000 rows in the table, the polygons are stored in a geometry field.
The issue I have is that many of the polygons cover a large portion of the globe. This seems to make it very hard to get a spatial index that will eliminate many rows in the primary filter. For example, look at the following query:
SELECT "ID","CODE","geom".STAsBinary() as "geom" FROM "dbo"."ContA"
WHERE "geom".Filter(
geometry::STGeomFromText('POLYGON ((-142.03193662573682 59.53396984952896,
-142.03193662573682 59.88928136451884,
-141.32743833481925 59.88928136451884,
-141.32743833481925 59.53396984952896,
-142.03193662573682 59.53396984952896))', 4326)
) = 1
This is querying an area which intersects with only two of the polygons in the table. No matter what combination of spatial index settings I chose, that Filter() always returns around 60,000 rows.
Replacing Filter() with STIntersects() of course returns just the two polygons I want, but of course takes much longer (Filter() is 6 seconds, STIntersects() is 12 seconds).
Can anyone give me any hints on whether there is a spatial index setup that is likely to improve on 60,000 rows or is my dataset just not a good match for SQL Server's spatial indexing ?
More info:
As suggested, I split the polygons up, using a 4x4 grid across the globe. I couldn't see a way to do it with QGIS, so I wrote my own query to do it. First I defined 16 bounding boxes, the first looked like this:
declare @box1 geometry = geometry::STGeomFromText('POLYGON ((
-180 90,
-90 90,
-90 45,
-180 45,
-180 90))', 4326)
Then I used each bounding box to select and truncate the polygons that intersected that box:
insert ContASplit
select CODE, geom.STIntersection(@box1), CODE_DESC from ContA
where geom.STIntersects(@box1) = 1
I obviously did this for all 16 bounding boxes in the 4x4 grid. The end result is that I have a new table with ~107,000 rows (which confirms that I didn't actually have many huge polygons).
I added a spatial index with 1024 cells per object and low,low,low,low for the cells per level.
However, very oddly this new table with the split polygons still performs the same as the old one. Doing the .Filter listed above still returns ~60,000 rows. I really don't understand this at all, clearly I don't understand how the spatial index actually work.
Paradoxically, while .Filter() still returns ~60,000 rows, it has improved performance. The .Filter() now takes around 2 seconds rather than 6 and the .STIntersects() now takes 6 seconds rather than 12.
As requested here is an example of the SQL for the index:
CREATE SPATIAL INDEX [contasplit_sidx] ON [dbo].[ContASplit]
(
[geom]
)USING GEOMETRY_GRID
WITH (
BOUNDING_BOX =(-90, -180, 90, 180),
GRIDS =(LEVEL_1 = LOW,LEVEL_2 = LOW,LEVEL_3 = LOW,LEVEL_4 = LOW),
CELLS_PER_OBJECT = 1024,
PAD_INDEX = OFF,
SORT_IN_TEMPDB = OFF,
DROP_EXISTING = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
Though remember, I have tried a whole range of different settings for the grids and cells per object, with the same results each time.
Here are the results of running sp_help_spatial_geometry_index, this is on my split dataset where no single polygon occupies more than 1/16th of the globe:
Base_Table_Rows 215138 Bounding_Box_xmin -90 Bounding_Box_ymin -180 Bounding_Box_xmax 90 Bounding_Box_ymax 180 Grid_Size_Level_1 64 Grid_Size_Level_2 64 Grid_Size_Level_3 64 Grid_Size_Level_4 64 Cells_Per_Object 16 Total_Primary_Index_Rows 378650 Total_Primary_Index_Pages 1129 Average_Number_Of_Index_Rows_Per_Base_Row 1 Total_Number_Of_ObjectCells_In_Level0_For_QuerySample 1 Total_Number_Of_ObjectCells_In_Level0_In_Index 60956 Total_Number_Of_ObjectCells_In_Level1_In_Index 361 Total_Number_Of_ObjectCells_In_Level2_In_Index 2935 Total_Number_Of_ObjectCells_In_Level3_In_Index 32420 Total_Number_Of_ObjectCells_In_Level4_In_Index 281978 Total_Number_Of_Interior_ObjectCells_In_Level2_In_Index 1 Total_Number_Of_Interior_ObjectCells_In_Level3_In_Index 49 Total_Number_Of_Interior_ObjectCells_In_Level4_In_Index 4236 Total_Number_Of_Intersecting_ObjectCells_In_Level1_In_Index 29 Total_Number_Of_Intersecting_ObjectCells_In_Level2_In_Index 1294 Total_Number_Of_Intersecting_ObjectCells_In_Level3_In_Index 29680 Total_Number_Of_Intersecting_ObjectCells_In_Level4_In_Index 251517 Total_Number_Of_Border_ObjectCells_In_Level0_For_QuerySample 1 Total_Number_Of_Border_ObjectCells_In_Level0_In_Index 60956 Total_Number_Of_Border_ObjectCells_In_Level1_In_Index 332 Total_Number_Of_Border_ObjectCells_In_Level2_In_Index 1640 Total_Number_Of_Border_ObjectCells_In_Level3_In_Index 2691 Total_Number_Of_Border_ObjectCells_In_Level4_In_Index 26225 Interior_To_Total_Cells_Normalized_To_Leaf_Grid_Percentage 0.004852925 Intersecting_To_Total_Cells_Normalized_To_Leaf_Grid_Percentage 0.288147586 Border_To_Total_Cells_Normalized_To_Leaf_Grid_Percentage 99.70699949 Average_Cells_Per_Object_Normalized_To_Leaf_Grid 405.7282349 Average_Objects_PerLeaf_GridCell 0.002464704 Number_Of_SRIDs_Found 1 Width_Of_Cell_In_Level1 2.8125 Width_Of_Cell_In_Level2 0.043945313 Width_Of_Cell_In_Level3 0.000686646 Width_Of_Cell_In_Level4 1.07E-05 Height_Of_Cell_In_Level1 5.625 Height_Of_Cell_In_Level2 0.087890625 Height_Of_Cell_In_Level3 0.001373291 Height_Of_Cell_In_Level4 2.15E-05 Area_Of_Cell_In_Level1 1012.5 Area_Of_Cell_In_Level2 15.8203125 Area_Of_Cell_In_Level3 0.247192383 Area_Of_Cell_In_Level4 0.003862381 CellArea_To_BoundingBoxArea_Percentage_In_Level1 1.5625 CellArea_To_BoundingBoxArea_Percentage_In_Level2 0.024414063 CellArea_To_BoundingBoxArea_Percentage_In_Level3 0.00038147 CellArea_To_BoundingBoxArea_Percentage_In_Level4 5.96E-06 Number_Of_Rows_Selected_By_Primary_Filter 60956 Number_Of_Rows_Selected_By_Internal_Filter 0 Number_Of_Times_Secondary_Filter_Is_Called 60956 Number_Of_Rows_Output 2 Percentage_Of_Rows_NotSelected_By_Primary_Filter 71.66655821 Percentage_Of_Primary_Filter_Rows_Selected_By_Internal_Filter 0 Internal_Filter_Efficiency 0 Primary_Filter_Efficiency 0.003281055
"Base_Table_Rows 215138" doesn't make much sense to me, there are 107,000 rows in the table, not 215,000
When rendered the data set looks like this:
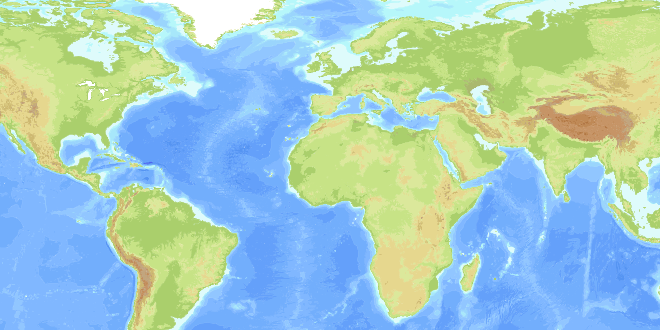
(source: norman.cx)
{kind=link}
Further research:
I continue to be puzzled by the poor performance of the primary filter with this data. So I did a test to see exactly how my data splits up. With my original unsplit features I added a "cells" column to the table. I then ran 16 queries to count how many cells in a 4x4 grid the feature spanned. So I ran a query like this for each cell:
declare @box1 geometry = geometry::STGeomFromText('POLYGON ((
-180 90,
-90 90,
-90 45,
-180 45,
-180 90))', 4326)
update ContA set cells = cells + 1 where
geom.STIntersects(@box1) = 1
If I then look at the "cells" column in the table there are only 672 features in the whole of my data set that intersect with more than 1 cell within the 4x4 grid. So how on Earth, quite literally, can the primary filter be returning 60,000 features for a query looking at a small 200 mile wide rectangle ?
At this point it looks like I could write my own indexing scheme that would work better that how SQL Server's is performing for these features.