No, Pharo and its VM do not optimize recursive tail calls.
It is apparent from running tests on a Pharo 9 image, and this master thesis on the subject confirms that.
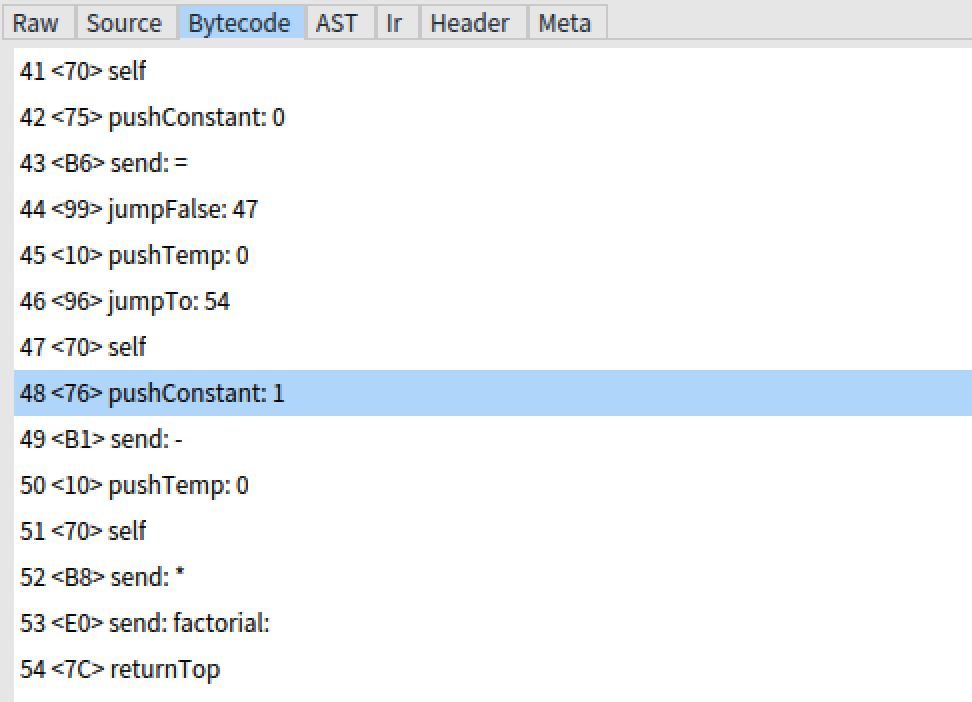
As of today Pharo ships with two factorial methods, one (Integer >> factorial) uses a 2-partition algorithm and is the most efficient, the other looks like this:
Integer >> slowFactorial [
self > 0
ifTrue: [ ^ self * (self - 1) factorial ].
self = 0
ifTrue: [ ^ 1 ].
self error: 'Not valid for negative integers'
]
It has an outer recursive structure, but actually still calls the non-recursive factorial method. That probably explains why Massimo Nocentini got nearly identical results when he timed them.
If we try this modified version:
Integer >> recursiveFactorial [
self > 0
ifTrue: [ ^ self * (self - 1) recursiveFactorial ].
self = 0
ifTrue: [ ^ 1 ].
self error: 'Not valid for negative integers'
]
we now have a real recursive method, but, as Massimo pointed out, it's still not tail recursive.
This is tail recursive:
tailRecursiveFactorial: acc
^ self = 0
ifTrue: [ acc ]
ifFalse: [ self - 1 tailRecursiveFactorial: acc * self ]
Without tail call optimization this version shows by far the worst performance, even compared to recursiveFactorial. I think that's because it burdens the stack with all the redundant intermediate results.
{kind=link}
ifTrue:case and just count the number of times the same method is on the stack... ;-) – Emetine