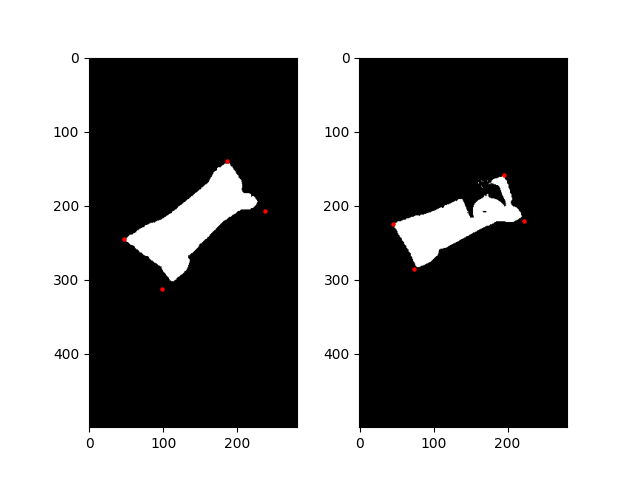
The blue and green in those images are really close to each other color-wise ([80,95] vs [97, 101] on the Hue Channel). Unfortunately light-blue and green are right next to each other as colors. I tried it in both the HSV and LAB color spaces to see if I could get better separation in one vs the other.
I aligned the images using feature matching as you mentioned. We can see that the perspective difference causes bits of the candy to poke out (the blue bits)
![enter image description here]()
I made a mask based on the pixel-wise difference in color between the two.
![enter image description here]()
There's a lot of bits sticking out because the images don't line up perfectly. To help deal with this we can also check a square region around each pixel to see if any of its nearby neighbors match its color. If it does, we'll remove it from the mask.
![enter image description here]()
We can use this to paint on the original image to mark what's different.
![enter image description here]()
Here's the results from the LAB version of the code
![enter image description here]()
I'll include both versions of the code here. They're interactive with 'WASD' to change the two parameters (color margin and fuzz margin). The color_margin represents how different two colors have to be to no longer be considered the same. The fuzz_margin is how far to look around the pixel for a matching color.
lab_version.py
import cv2
import numpy as np
# returns the difference mask between two single-channel images
def diffChannel(one, two, margin):
# get the largest difference per pixel
diff = np.maximum(cv2.subtract(one, two), cv2.subtract(two, one));
# mask on margin
mask = cv2.inRange(diff, margin, 255);
return mask;
# returns difference between colors of two image in the LAB colorspace
# (ignores the L channel) <- the 'L' channel holds how bright the image is
def labDiff(one, two, margin):
# split
l1,a1,b1 = cv2.split(one);
l2,a2,b2 = cv2.split(two);
# do a diff on the 'a' and 'b' channels
a_mask = diffChannel(a1, a2, margin);
b_mask = diffChannel(b1, b2, margin);
# combine masks
mask = cv2.bitwise_or(a_mask, b_mask);
return mask;
# add/remove margin to all sides of an image
def addMargin(img, margin):
return cv2.copyMakeBorder(img, margin, margin, margin, margin, cv2.BORDER_CONSTANT, 0);
def removeMargin(img, margin):
return img[margin:-margin, margin:-margin];
# fuzzy match the masked pixels to clean up small differences in the image
def fuzzyMatch(src, dst, mask, margin, radius):
# add margins to prevent out-of-bounds error
src = addMargin(src, radius);
dst = addMargin(dst, radius);
mask = addMargin(mask, radius);
# do a search on a square window
size = radius * 2 + 1;
# get mask points
temp = np.where(mask == 255);
points = [];
for a in range(len(temp[0])):
y = temp[0][a];
x = temp[1][a];
points.append([x,y]);
# do a fuzzy match on each position
for point in points:
# unpack
x,y = point;
# calculate slice positions
left = x - radius;
right = x + radius + 1;
top = y - radius;
bottom = y + radius + 1;
# make color window
color_window = np.zeros((size, size, 3), np.uint8);
color_window[:] = src[y,x];
# do a lab diff with dest
dst_slice = dst[top:bottom, left:right];
diff = labDiff(color_window, dst_slice, margin);
# if any part of the diff is false, erase from mask
if np.any(diff != 255):
mask[y,x] = 0;
# remove margins
src = removeMargin(src, radius);
dst = removeMargin(dst, radius);
mask = removeMargin(mask, radius);
return mask;
# params
color_margin = 15;
fuzz_margin = 5;
# load images
left = cv2.imread("left.jpg");
right = cv2.imread("right.jpg");
# align
# get keypoints
sift = cv2.SIFT_create();
kp1, des1 = sift.detectAndCompute(left, None);
kp2, des2 = sift.detectAndCompute(right, None);
# match
bfm = cv2.BFMatcher();
matches = bfm.knnMatch(des1, des2, k=2); # only get two possible matches
# ratio test (reject matches that are close together)
# these features are typically repetitive, and close together (like teeth on a comb)
# and are very likely to match onto the wrong one causing misalignment
cleaned = [];
for a,b in matches:
if a.distance < 0.7 * b.distance:
cleaned.append(a);
# calculate homography
src = np.float32([kp1[a.queryIdx].pt for a in cleaned]).reshape(-1,1,2);
dst = np.float32([kp2[a.trainIdx].pt for a in cleaned]).reshape(-1,1,2);
hmat, _ = cv2.findHomography(src, dst, cv2.RANSAC, 5.0);
# warp left
h,w = left.shape[:2];
left = cv2.warpPerspective(left, hmat, (w,h));
# mask left
mask = np.zeros((h,w), np.uint8);
mask[:] = 255;
warp_mask = cv2.warpPerspective(mask, hmat, (w,h));
# difference check
# change to a less light-sensitive color space
left_lab = cv2.cvtColor(left, cv2.COLOR_BGR2LAB);
right_lab = cv2.cvtColor(right, cv2.COLOR_BGR2LAB);
# tweak params
done = False;
while not done:
diff_mask = labDiff(left_lab, right_lab, color_margin);
# combine with warp mask (get rid of the blank space after the warp)
diff_mask = cv2.bitwise_and(diff_mask, warp_mask);
# do fuzzy matching to clean up mask pixels
before = np.copy(diff_mask);
diff_mask = fuzzyMatch(left_lab, right_lab, diff_mask, color_margin, fuzz_margin);
# open (erode + dilate) to clean up small dots
kernel = np.ones((5,5), np.uint8);
diff_mask = cv2.morphologyEx(diff_mask, cv2.MORPH_OPEN, kernel);
# pull just the diff
just_diff = np.zeros_like(right);
just_diff[diff_mask == 255] = right[diff_mask == 255];
copy = np.copy(right);
copy[diff_mask == 255] = (0,255,0);
# show
cv2.imshow("Right", copy);
cv2.imshow("Before Fuzz", before);
cv2.imshow("After Fuzz", diff_mask);
cv2.imshow("Just the Diff", just_diff);
key = cv2.waitKey(0);
cv2.imwrite("mark2.png", copy);
# check key
done = key == ord('q');
change = False;
if key == ord('d'):
color_margin += 1;
change = True;
if key == ord('a'):
color_margin -= 1;
change = True;
if key == ord('w'):
fuzz_margin += 1;
change = True;
if key == ord('s'):
fuzz_margin -= 1;
change = True;
# print vals
if change:
print("Color: " + str(color_margin) + " || Fuzz: " + str(fuzz_margin));
hsv_version.py
import cv2
import numpy as np
# returns the difference mask between two single-channel images
def diffChannel(one, two, margin):
# get the largest difference per pixel
diff = np.maximum(cv2.subtract(one, two), cv2.subtract(two, one));
# mask on margin
mask = cv2.inRange(diff, margin, 255);
return mask;
# returns difference between colors of two images in the LAB colorspace
# (ignores the L channel) <- the 'L' channel holds how bright the image is
def labDiff(one, two, margin):
# split
l1,a1,b1 = cv2.split(one);
l2,a2,b2 = cv2.split(two);
# do a diff on the 'a' and 'b' channels
a_mask = diffChannel(a1, a2, margin);
b_mask = diffChannel(b1, b2, margin);
# combine masks
mask = cv2.bitwise_or(a_mask, b_mask);
return mask;
# returns the difference between colors of two images in the HSV colorspace
# the 'H' channel is hue (color)
def hsvDiff(one, two, margin):
# split
h1,s1,v1 = cv2.split(one);
h2,s2,v2 = cv2.split(two);
# do a diff on the 'h' channel
h_mask = diffChannel(h1, h2, margin);
return h_mask;
# add/remove margin to all sides of an image
def addMargin(img, margin):
return cv2.copyMakeBorder(img, margin, margin, margin, margin, cv2.BORDER_CONSTANT, 0);
def removeMargin(img, margin):
return img[margin:-margin, margin:-margin];
# fuzzy match the masked pixels to clean up small differences in the image
def fuzzyMatch(src, dst, mask, margin, radius):
# add margins to prevent out-of-bounds error
src = addMargin(src, radius);
dst = addMargin(dst, radius);
mask = addMargin(mask, radius);
# do a search on a square window
size = radius * 2 + 1;
# get mask points
temp = np.where(mask == 255);
points = [];
for a in range(len(temp[0])):
y = temp[0][a];
x = temp[1][a];
points.append([x,y]);
print("Num Points in Mask: " + str(len(points)));
# do a fuzzy match on each position
for point in points:
# unpack
x,y = point;
# calculate slice positions
left = x - radius;
right = x + radius + 1;
top = y - radius;
bottom = y + radius + 1;
# make color window
color_window = np.zeros((size, size, 3), np.uint8);
color_window[:] = src[y,x];
# do a lab diff with dest
dst_slice = dst[top:bottom, left:right];
diff = hsvDiff(color_window, dst_slice, margin);
# diff = labDiff(color_window, dst_slice, margin);
# if any part of the diff is false, erase from mask
if np.any(diff != 255):
mask[y,x] = 0;
# remove margins
src = removeMargin(src, radius);
dst = removeMargin(dst, radius);
mask = removeMargin(mask, radius);
return mask;
# params
color_margin = 15;
fuzz_margin = 5;
# load images
left = cv2.imread("left.jpg");
right = cv2.imread("right.jpg");
# align
# get keypoints
sift = cv2.SIFT_create();
kp1, des1 = sift.detectAndCompute(left, None);
kp2, des2 = sift.detectAndCompute(right, None);
# match
bfm = cv2.BFMatcher();
matches = bfm.knnMatch(des1, des2, k=2); # only get two possible matches
# ratio test (reject matches that are close together)
# these features are typically repetitive, and close together (like teeth on a comb)
# and are very likely to match onto the wrong one causing misalignment
cleaned = [];
for a,b in matches:
if a.distance < 0.7 * b.distance:
cleaned.append(a);
# calculate homography
src = np.float32([kp1[a.queryIdx].pt for a in cleaned]).reshape(-1,1,2);
dst = np.float32([kp2[a.trainIdx].pt for a in cleaned]).reshape(-1,1,2);
hmat, _ = cv2.findHomography(src, dst, cv2.RANSAC, 5.0);
# warp left
h,w = left.shape[:2];
left = cv2.warpPerspective(left, hmat, (w,h));
# mask left
mask = np.zeros((h,w), np.uint8);
mask[:] = 255;
warp_mask = cv2.warpPerspective(mask, hmat, (w,h));
# difference check
# change to a less light-sensitive color space
left_hsv = cv2.cvtColor(left, cv2.COLOR_BGR2HSV);
right_hsv = cv2.cvtColor(right, cv2.COLOR_BGR2HSV);
# loop
done = False;
color_margin = 5;
fuzz_margin = 5;
while not done:
diff_mask = hsvDiff(left_hsv, right_hsv, color_margin);
# combine with warp mask (get rid of the blank space after the warp)
diff_mask = cv2.bitwise_and(diff_mask, warp_mask);
# do fuzzy matching to clean up mask pixels
before = np.copy(diff_mask);
diff_mask = fuzzyMatch(left_hsv, right_hsv, diff_mask, color_margin, fuzz_margin);
# open (erode + dilate) to clean up small dots
kernel = np.ones((5,5), np.uint8);
diff_mask = cv2.morphologyEx(diff_mask, cv2.MORPH_OPEN, kernel);
# get channel
h1,_,_ = cv2.split(left_hsv);
h2,_,_ = cv2.split(right_hsv);
# copy
copy = np.copy(right);
copy[diff_mask == 255] = (0,255,0);
# show
cv2.imshow("Left hue", h1);
cv2.imshow("Right hue", h2);
cv2.imshow("Mark", copy);
cv2.imshow("Before", before);
cv2.imshow("Diff", diff_mask);
key = cv2.waitKey(0);
cv2.imwrite("mark1.png", copy);
# check key
done = key == ord('q');
change = False;
if key == ord('d'):
color_margin += 1;
change = True;
if key == ord('a'):
color_margin -= 1;
change = True;
if key == ord('w'):
fuzz_margin += 1;
change = True;
if key == ord('s'):
fuzz_margin -= 1;
change = True;
# print vals
if change:
print("Color: " + str(color_margin) + " || Fuzz: " + str(fuzz_margin));