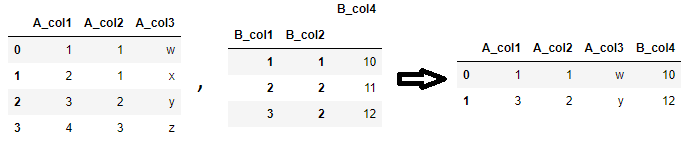
I am trying to join two pandas dataframes using two columns:
new_df = pd.merge(A_df, B_df, how='left', left_on='[A_c1,c2]', right_on = '[B_c1,c2]')
but got the following error:
pandas/index.pyx in pandas.index.IndexEngine.get_loc (pandas/index.c:4164)()
pandas/index.pyx in pandas.index.IndexEngine.get_loc (pandas/index.c:4028)()
pandas/src/hashtable_class_helper.pxi in pandas.hashtable.PyObjectHashTable.get_item (pandas/hashtable.c:13166)()
pandas/src/hashtable_class_helper.pxi in pandas.hashtable.PyObjectHashTable.get_item (pandas/hashtable.c:13120)()
KeyError: '[B_1, c2]'
Any idea what should be the right way to do this?



left_onandright_onshould be a list of strings, not a string that looks like a list. – Scientific