I have a skewed data in a table which is then compared with other table that is small. I understood that salting works in case of joins- that is a random number is appended to keys in big table with skew data from a range of random data and the rows in small table with no skew data are duplicated with the same range of random numbers. Hence the matching happens because there will be a hit in one among the duplicate values for particular salted key of skewed able. I also read that salting is helpful while performing groupby. My question is when random numbers are appended to the key doesn't it break the group? If it does then the meaning of group by operation has changed.
spark: How does salting work in dealing with skewed data
Asked Answered
My question is when random numbers are appended to the key doesn't it break the group?
Well, it does, to mitigate this you could run group by operation twice. Firstly with salted key, then remove salting and group again. The second grouping will take partially aggregated data, thus significantly reduce skew impact.
E.g.
import org.apache.spark.sql.functions._
df.withColumn("salt", (rand * n).cast(IntegerType))
.groupBy("salt", groupByFields)
.agg(aggFields)
.groupBy(groupByFields)
.agg(aggFields)
if the aggregation functions are like count, percentile and standardDeviation will this produce correct results, I know for sum, it will be efficient this way but not sure for the count, percentile, and standardDev it will provide the correct results. –
Kraut
what if we try to create new column using substring on skewed column? –
Flipflop
"My question is when random numbers are appended to the key doesn't it break the group? If if does then the meaning of group by operation has changed."
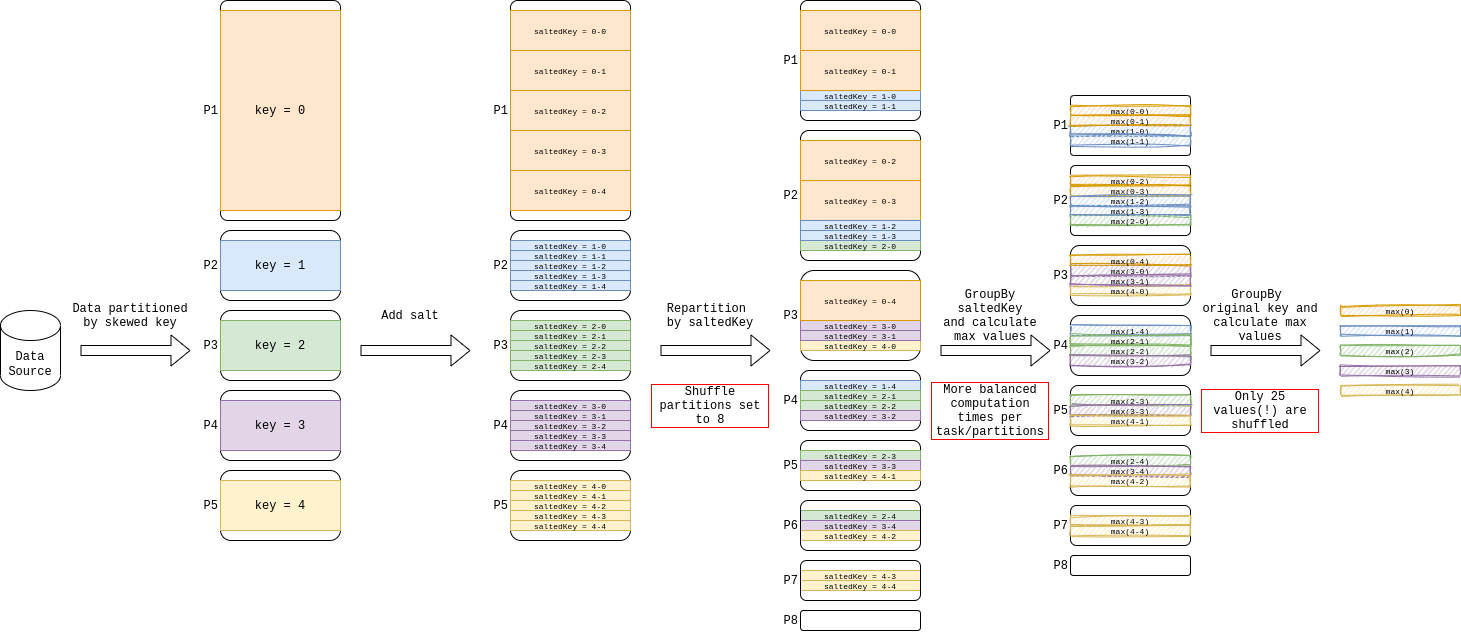
Yes, adding a salt to an existing key will break the group. However, as @Gelerion has mentioned in his answer, you can group by the salted and original key and afterwards group by the original key. This works well for aggregations such as
- count
- min
- max
- sum
where it is possible to combine results from sub-groups. The illustration below shows an example of calculating the maximum value of a skewed Dataframe.
I'd really love to see the whole comparison of the query plans and performances of without- and with-salt computations. –
Forsaken
var df1 = Seq((1,"a"),(2,"b"),(1,"c"),(1,"x"),(1,"y"),(1,"g"),(1,"k"),(1,"u"),(1,"n")).toDF("ID","NAME")
df1.createOrReplaceTempView("fact")
var df2 = Seq((1,10),(2,30),(3,40)).toDF("ID","SALARY")
df2.createOrReplaceTempView("dim")
val salted_df1 = spark.sql("""select concat(ID, '_', FLOOR(RAND(123456)*19)) as salted_key, NAME from fact """)
salted_df1.createOrReplaceTempView("salted_fact")
val exploded_dim_df = spark.sql(""" select ID, SALARY, explode(array(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19)) as salted_key from dim""")
//val exploded_dim_df = spark.sql(""" select ID, SALARY, explode(array(0 to 19)) as salted_key from dim""")
exploded_dim_df.createOrReplaceTempView("salted_dim")
val result_df = spark.sql("""select split(fact.salted_key, '_')[0] as ID, dim.SALARY
from salted_fact fact
LEFT JOIN salted_dim dim
ON fact.salted_key = concat(dim.ID, '_', dim.salted_key) """)
display(result_df)
© 2022 - 2025 — McMap. All rights reserved.