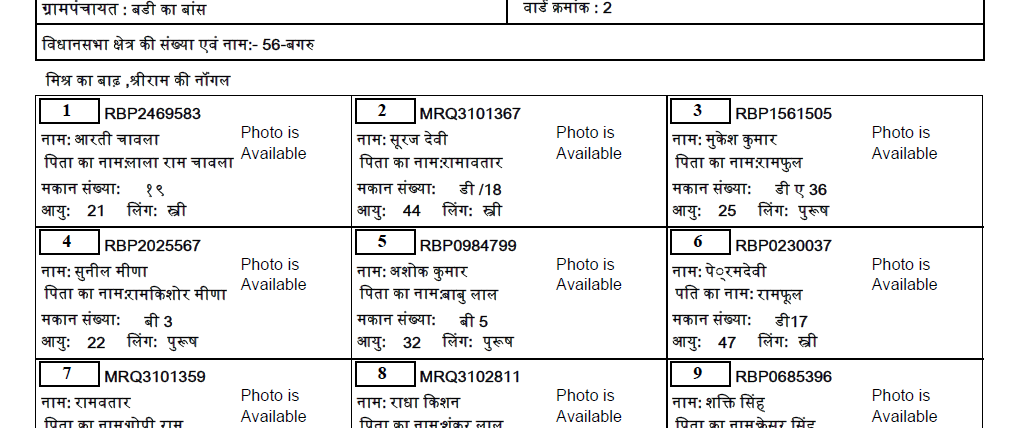
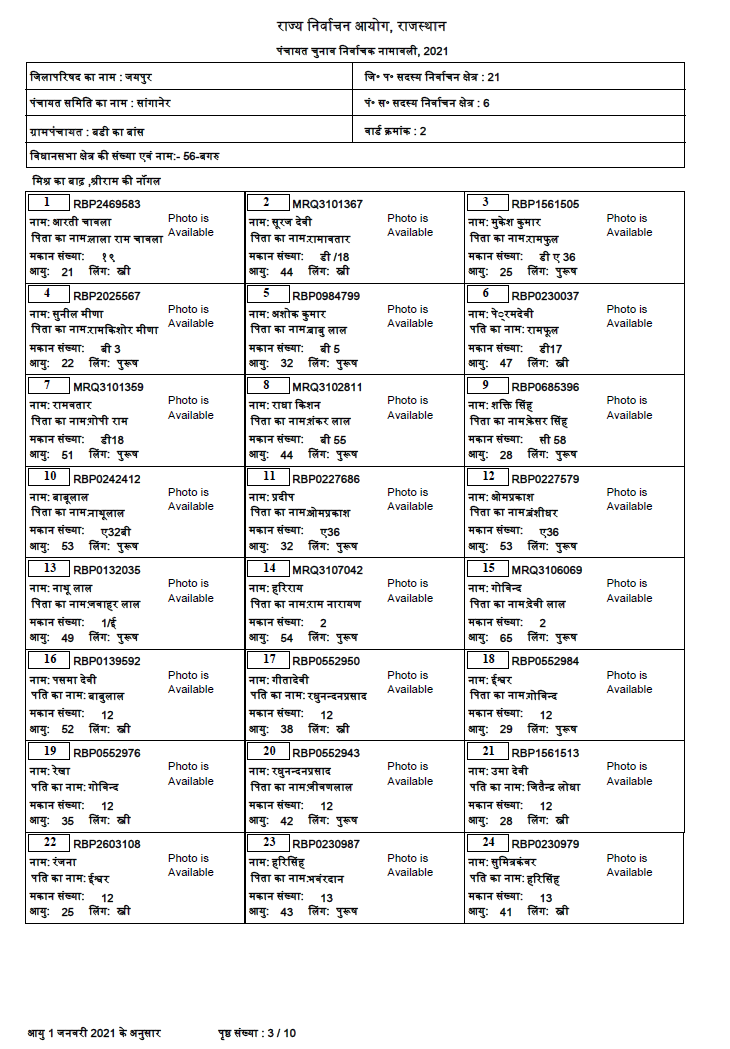
I will give some ideas how to process your image, but I will limit that to page 3 of the given document, i.e. the page shown in the question.
For converting the PDF page to some image, I used pdf2image.
For the OCR, I use pytesseract, but instead of lang='hin', I use lang='Devanagari', cf. the Tesseract GitHub. In general, make sure to work through Improving the quality of the output from the Tesseract documentation, especially the page segmentation method.
Here's a (lengthy) description of the whole procedure:
- Inverse binarize the image for contour finding: white texts, shapes, etc. on black background.
- Find all contours, and filter out the two very large contours, i.e. these are the two tables.
- Extract texts outside of the two tables:
- Mask out tables in the binarized image.
- Do morphological closing to connect remaining lines of text.
- Find contours, and bounding rectangles of these lines of text.
- Run
pytesseract to extract the texts.
- Extract texts inside of the two tables:
- Extract the cells, better: their bounding rectangles, from the current table.
- For the first table:
- Run
pytesseract to extract the texts as-is.
- For the second table:
- Floodfill the rectangle around the number to prevent faulty OCR output.
- Mask the left (Hindi) and right (English) part.
- Run
pytesseract using lang='Devaganari' on the left, and using lang='eng' on the right part to improve OCR quality for both.
That'd be the whole code:
import cv2
import numpy as np
import pdf2image
import pytesseract
# Extract page 3 from PDF in proper quality
page_3 = np.array(pdf2image.convert_from_path('BADI KA BANS-Ward No-002.pdf',
first_page=3, last_page=3,
dpi=300, grayscale=True)[0])
# Inverse binarize for contour finding
thr = cv2.threshold(page_3, 128, 255, cv2.THRESH_BINARY_INV)[1]
# Find contours w.r.t. the OpenCV version
cnts = cv2.findContours(thr, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
# STEP 1: Extract texts outside of the two tables
# Mask out the two tables
cnts_tables = [cnt for cnt in cnts if cv2.contourArea(cnt) > 10000]
no_tables = cv2.drawContours(thr.copy(), cnts_tables, -1, 0, cv2.FILLED)
# Find bounding rectangles of texts outside of the two tables
no_tables = cv2.morphologyEx(no_tables, cv2.MORPH_CLOSE, np.full((21, 51), 255))
cnts = cv2.findContours(no_tables, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
rects = sorted([cv2.boundingRect(cnt) for cnt in cnts], key=lambda r: r[1])
# Extract texts from each bounding rectangle
print('\nExtract texts outside of the two tables\n')
for (x, y, w, h) in rects:
text = pytesseract.image_to_string(page_3[y:y+h, x:x+w],
config='--psm 6', lang='Devanagari')
text = text.replace('\n', '').replace('\f', '')
print('x: {}, y: {}, text: {}'.format(x, y, text))
# STEP 2: Extract texts from inside of the two tables
rects = sorted([cv2.boundingRect(cnt) for cnt in cnts_tables],
key=lambda r: r[1])
# Iterate each table
for i_r, (x, y, w, h) in enumerate(rects, start=1):
# Find bounding rectangles of cells inside of the current table
cnts = cv2.findContours(page_3[y+2:y+h-2, x+2:x+w-2],
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
inner_rects = sorted([cv2.boundingRect(cnt) for cnt in cnts],
key=lambda r: (r[1], r[0]))
# Extract texts from each cell of the current table
print('\nExtract texts inside table {}\n'.format(i_r))
for (xx, yy, ww, hh) in inner_rects:
# Set current coordinates w.r.t. full image
xx += x
yy += y
# Get current cell
cell = page_3[yy+2:yy+hh-2, xx+2:xx+ww-2]
# For table 1, simply extract texts as-is
if i_r == 1:
text = pytesseract.image_to_string(cell, config='--psm 6',
lang='Devanagari')
text = text.replace('\n', '').replace('\f', '')
print('x: {}, y: {}, text: {}'.format(xx, yy, text))
# For table 2, extract single elements
if i_r == 2:
# Floodfill rectangles around numbers
ys, xs = np.min(np.argwhere(cell == 0), axis=0)
temp = cv2.floodFill(cell.copy(), None, (xs, ys), 255)[1]
mask = cv2.floodFill(thr[yy+2:yy+hh-2, xx+2:xx+ww-2].copy(),
None, (xs, ys), 0)[1]
# Extract left (Hindi) and right (English) parts
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE,
np.full((2 * hh, 5), 255))
cnts = cv2.findContours(mask,
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
boxes = sorted([cv2.boundingRect(cnt) for cnt in cnts],
key=lambda b: b[0])
# Extract texts from each part of the current cell
for i_b, (x_b, y_b, w_b, h_b) in enumerate(boxes, start=1):
# For the left (Hindi) part, extract Hindi texts
if i_b == 1:
text = pytesseract.image_to_string(
temp[y_b:y_b+h_b, x_b:x_b+w_b],
config='--psm 6',
lang='Devanagari')
text = text.replace('\f', '')
# For the left (English) part, extract English texts
if i_b == 2:
text = pytesseract.image_to_string(
temp[y_b:y_b+h_b, x_b:x_b+w_b],
config='--psm 6',
lang='eng')
text = text.replace('\f', '')
print('x: {}, y: {}, text:\n{}'.format(xx, yy, text))
And, here are the first few lines of the output:
Extract texts outside of the two tables
x: 972, y: 93, text: राज्य निर्वाचन आयोग, राजस्थान
x: 971, y: 181, text: पंचायत चुनाव निर्वाचक नामावली, 2021
x: 166, y: 610, text: मिश्र का बाढ़ ,श्रीराम की नॉगल
x: 151, y: 3417, text: आयु 1 जनवरी 2021 के अनुसार
x: 778, y: 3419, text: पृष्ठ संख्या : 3 / 10
Extract texts inside table 1
x: 146, y: 240, text: जिलापरिषद का नाम : जयपुर
x: 1223, y: 240, text: जि° प° सदस्य निर्वाचन क्षेत्र : 21
x: 146, y: 327, text: पंचायत समिति का नाम : सांगानेर
x: 1223, y: 327, text: पं° स° सदस्य निर्वाचन क्षेत्र : 6
x: 146, y: 415, text: ग्रामपंचायत : बडी का बांस
x: 1223, y: 415, text: वार्ड क्रमांक : 2
x: 146, y: 502, text: विधानसभा क्षेत्र की संख्या एवं नाम:- 56-बगरु
Extract texts inside table 2
x: 142, y: 665, text:
1 RBP2469583
नाम: आरती चावला
पिता का नामःलाला राम चावला
मकान संख्याः १९
आयुः 21 लिंगः स्त्री
x: 142, y: 665, text:
Photo is
Available
x: 867, y: 665, text:
2 MRQ3101367
नामः सूरज देवी
पिता का नामःरामावतार
मकान संख्याः डी /18
आयुः 44 लिंगः स्त्री
x: 867, y: 665, text:
Photo is
Available
I checked a few texts using manual character-by-character comparison, and thought it looked quite good, but unable to understand Hindi or reading Devanagari script, I can't comment on the overall quality of the OCR. Please let me know!
Annoyingly, the number 9 from the corresponding "card" is falsely extracted as 2. I assume, that happens due to the different font compared to the rest of the text, and in combination with lang='Devanagari'. Couldn't find a solution for that – without extracting the rectangle separately from the "card".
----------------------------------------
System information
----------------------------------------
Platform: Windows-10-10.0.19041-SP0
Python: 3.9.1
PyCharm: 2021.1.1
NumPy: 1.19.5
OpenCV: 4.5.2
pdf2image 1.14.0
pytesseract: 5.0.0-alpha.20201127
----------------------------------------