Setting a texture on the GPU takes some CPU time, but it is reasonably small in comparison to the actual batch cost. More importantly, it should have no impact at all on the actual shader execution, if the shader never references it.
Now, there are three ways that branching can be handled:
First of all, if the branch condition is always going to be the same thing (if it only depends on compile-time constants), then one side of the branch can be inlined out entirely. In many cases it can be preferable to compile multiple versions of your shader if it makes it possible to eliminate significant branches this way.
The second technique is that the shader can evaluate both sides of the branch and then select the correct result based on the conditional, all without actually branching (it does it arithmetically). This is best when the code in the branch is small.
And finally, it can actually use branching instructions. First of all the branch instructions have modest instruction count costs. And then there is the pipeline. The x86 has a long serial pipeline, which you can easily stall. The GPU has a completely different, parallel pipeline.
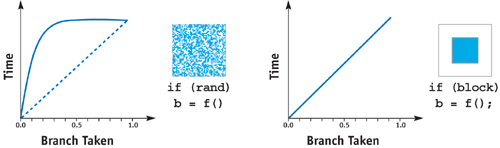
The GPU evaluates groups of fragments (pixels) in parallel, executing the fragment program once for multiple fragments at a time. If all the fragments in a group take the same branch, then you only have that branch's execution cost. If they take two (or more) branches, then the shader must be executed multiple times, for that group of fragments, to cover all the branches.
Because the fragment groups have on-screen locality, it helps if your branches have similar on-screen locality. See this diagram:
![]()
(source: nvidia.com)
Now, the shader compiler generally does a very good job of selecting which of the last two methods to use (for the first method, the compiler will inline for you, but you have to make multiple shader versions yourself). But if you're optimising performance, it can be useful to see the actual output of the compiler. To this end, use fxc.exe in the DirectX SDK Utilities, with the /Fc <file> option, to get a disassembly view of the compiled shader.
(As this is performance advice: remember to always measure your performance, figure out what limits you're hitting, and then worry about optimising it. No point in optimising your shader branches if you're texture-fetch bound, for example.)
Additional reference: GPU Gems 2: Chapter 34. GPU Flow-Control Idioms.
{kind=link}
ifstatement, followed by a conditional move. That is regardless of any conditions or patterns, since it is all the hardware is capable of doing. For SM3 hardware, branch taken/not taken patterns play the major role, the actual branching is cheap (2-3 cycles), but performance is equal to the the slowest branch combination in the warp. – Benavides