I am using terraform resource google_dataflow_flex_template_job to deploy a Dataflow flex template job.
resource "google_dataflow_flex_template_job" "streaming_beam" {
provider = google-beta
name = "streaming-beam"
container_spec_gcs_path = module.streaming_beam_flex_template_file[0].fully_qualified_path
parameters = {
"input_subscription" = google_pubsub_subscription.ratings[0].id
"output_table" = "${var.project}:beam_samples.streaming_beam_sql"
"service_account_email" = data.terraform_remote_state.state.outputs.sa.email
"network" = google_compute_network.network.name
"subnetwork" = "regions/${google_compute_subnetwork.subnet.region}/subnetworks/${google_compute_subnetwork.subnet.name}"
}
}
Its all working fine however without my requesting it the job seems to be using flexible resource scheduling (flexRS) mode, I say this because the job takes about ten minutes to start and during that time has state=QUEUED which I think is only applicable to flexRS jobs.
Using flexRS mode is fine for production scenarios however I'm currently still developing my dataflow job and when doing so flexRS is massively inconvenient because it takes about 10 minutes to see the effect of any changes I might make, no matter how small.
In Enabling FlexRS it is stated
To enable a FlexRS job, use the following pipeline option: --flexRSGoal=COST_OPTIMIZED, where the cost-optimized goal means that the Dataflow service chooses any available discounted resources or --flexRSGoal=SPEED_OPTIMIZED, where it optimizes for lower execution time.
I then found the following statement:
To turn on FlexRS, you must specify the value COST_OPTIMIZED to allow the Dataflow service to choose any available discounted resources.
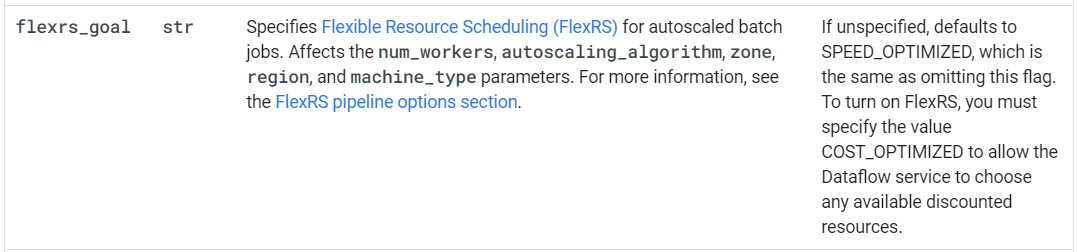
at Specifying pipeline execution parameters > Setting other Cloud Dataflow pipeline options
I interpret that to mean that flexrs_goal=SPEED_OPTIMIZED will turn off flexRS mode. However, I changed the definition of my google_dataflow_flex_template_job resource to:
resource "google_dataflow_flex_template_job" "streaming_beam" {
provider = google-beta
name = "streaming-beam"
container_spec_gcs_path = module.streaming_beam_flex_template_file[0].fully_qualified_path
parameters = {
"input_subscription" = google_pubsub_subscription.ratings[0].id
"output_table" = "${var.project}:beam_samples.streaming_beam_sql"
"service_account_email" = data.terraform_remote_state.state.outputs.sa.email
"network" = google_compute_network.network.name
"subnetwork" = "regions/${google_compute_subnetwork.subnet.region}/subnetworks/${google_compute_subnetwork.subnet.name}"
"flexrs_goal" = "SPEED_OPTIMIZED"
}
}
(note the addition of "flexrs_goal" = "SPEED_OPTIMIZED") but it doesn't seem to make any difference. The Dataflow UI confirms I have set SPEED_OPTIMIZED:
but it still takes too long (9 minutes 46 seconds) for the job to start processing data, and it was in state=QUEUED for all that time:
2021-01-17 19:49:19.021 GMTStarting GCE instance, launcher-2021011711491611239867327455334861, to launch the template.
...
...
2021-01-17 19:59:05.381 GMTStarting 1 workers in europe-west1-d...
2021-01-17 19:59:12.256 GMTVM, launcher-2021011711491611239867327455334861, stopped.
I then tried explictly setting flexrs_goal=COST_OPTIMIZED just to see if it made any difference, but this only caused an error:
"The workflow could not be created. Causes: The workflow could not be created due to misconfiguration. The experimental feature flexible_resource_scheduling is not supported for streaming jobs. Contact Google Cloud Support for further help. "
This makes sense. My job is indeed a streaming job and the documentation does indeed state that flexRS is only for batch jobs.
This page explains how to enable Flexible Resource Scheduling (FlexRS) for autoscaled batch pipelines in Dataflow.
https://cloud.google.com/dataflow/docs/guides/flexrs
This doesn't solve my problem though. As I said above if I deploy with flexrs_goal=SPEED_OPTIMIZED then still state=QUEUED for almost ten minutes, yet as far as I know QUEUED is only applicable to flexRS jobs:
Therefore, after you submit a FlexRS job, your job displays an ID and a Status of Queued
https://cloud.google.com/dataflow/docs/guides/flexrs#delayed_scheduling
Hence I'm very confused:
- Why is my job getting queued even though it is not a flexRS job?
- Why does it take nearly ten minutes for my job to start processing any data?
- How can I speed up the time it takes for my job to start processing data so that I can get quicker feedback during development/testing?
UPDATE, I dug a bit more into the logs to find out what was going on during those 9minutes 46 seconds. These two consecutive log messages are 7 minutes 23 seconds apart:
2021-01-17 19:51:03.381 GMT "INFO:apache_beam.runners.portability.stager:Executing command: ['/usr/local/bin/python', '-m', 'pip', 'download', '--dest', '/tmp/dataflow-requirements-cache', '-r', '/dataflow/template/requirements.txt', '--exists-action', 'i', '--no-binary', ':all:']"
2021-01-17 19:58:26.459 GMT "INFO:apache_beam.runners.portability.stager:Downloading source distribution of the SDK from PyPi"

Whatever is going on between those two log records is the main contributor to the long time spent in state=QUEUED. Anyone know what might be the cause?
INFO:apache_beam.runners.portability.stager:Executing command: ['/usr/local/bin/python', '-m', 'pip', 'download', '--dest', '/tmp/dataflow-requirements-cache', '-r', '/dataflow/template/requirements.txt', '--exists-action', 'i', '--no-binary', ':all:'– ThreefoldRUN pip install -U -r ./requirements.txtin my Dockerfile and just to prove it, if I remove that line from Dockerfile, build&push, then redeploy the flex template job the job fails quickly (i.e. prior to previous point of failure) with error "ModuleNotFoundError: No module named 'apache_beam'". – Inestimablemodule.streaming_beam_flex_template_file[0].fully_qualified_path, I'm try to build this template via terraform asked in #69348752, please provide the resource used. – Ilion