I am still struggling with identifying how the concept of table distribution in azure sql data warehouse differs from concept of table partition in Sql server?
Definition of both seems to be achieving same results.
I am still struggling with identifying how the concept of table distribution in azure sql data warehouse differs from concept of table partition in Sql server?
Definition of both seems to be achieving same results.
Azure DW has up to 60 computing nodes as part of it's MPP architecture. When you store a table on Azure DW you are storing it amongst those nodes. Your tables data is distributed across these nodes (using Hash distribution or Round Robin distribution depending on your needs). You can also choose to have your table (preferably a very small table) replicated across these nodes.

That is distribution. Each node has its own distinct records that only that node worries about when interacting with the data. It's a shared-nothing architecture.
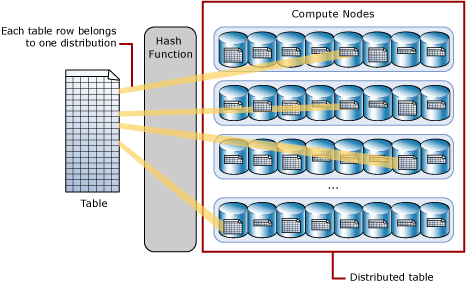
Partitioning is completely divorced from this concept of distribution. When we partition a table we decide which rows belong into which partitions based on some scheme (like partitioning an order table by the order.create_date for instance). A chunk of records for each create_date then gets stored in its own table separate from any other create_date set of records (invisibly behind the scenes).
Note that the rows in that partition table are then hashed and distributed across the available nodes as described above.
Partitioning is nice because you may find that you only want to select 10 days worth of orders from your table, so you only need to read against 10 smaller tables, instead of having to scan across years of order data to find the 10 days you are after.
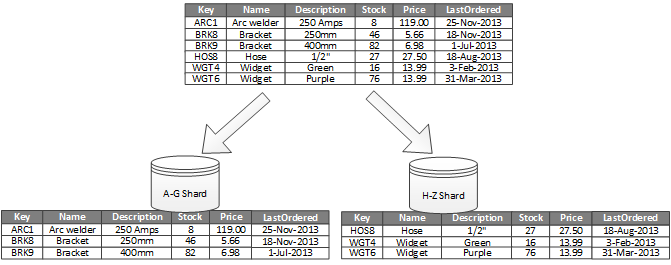
Here's an example from the Microsoft website where horizontal partitioning is done on the name column with two "shards" based on the names alphabetical order:
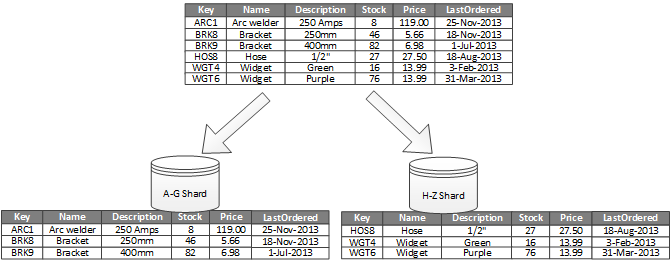
Table distribution is a concept that is only available on MPP type RDBMSs like Azure DW or Teradata. It's easiest to think of it as a hardware concept that is somewhat divorced (to a degree) from the data. Azure gives you a lot of control here where other MPP databases base distribution on primary keys. Partitioning is available on nearly every RDBMS (MPP or not) and it's easiest to think of it as a storage/software concept that is defined by and dependent on the data in the table.
In the end, they do both work to solve the same problem. But... nearly every RDBMS concept (indexing, disk storage, optimization, partition, distribution, etc) are there to solve the same problem. Namely: "How do I get the exact data I need out as quickly as possible?" When you combine these concepts together to match your data retrieval needs you make your SQL requests CRAZY fast even against monstrously huge data.
Just for fun, allow me to explain it with an analogy.
Suppose there exists one massive book about all history of the world. It has the size of a 42 story building.
Now what if the librarian splits that book into 1 book per year. That makes it much easier to find all information you need for some specific years. Because you can just keep the other books on the shelves.
A small book is easier to carry too.
That's what table partitioning is about. (Reference: Data Partitioning in Azure)
Keeping chunks of data together, based on a key (or set of columns) that is usefull for the majority of the queries and has a nice average distribution.
This can reduce IO because only the relevant chunks need to be accessed.
Now what if the chief librarian unbinds that book. And sends sets of pages to many different libraries.
When we then need certain information, we ask each library to send us copies of the pages we need.
Even better, those librarians could already summarize the information of their pages and then just send only their summaries to one library that collects them for you.
That's what the table distribution is about. (Reference: Table Distribution Guidance in Azure)
To spread out the data over the different nodes.
Conceptually they are the same. The basic idea is that the data will be split across multiple stores. However, the implementation is radically different. Under the covers, Azure SQL Data Warehouse manages and maintains the 70 databases that each table you define is created within. You do nothing beyond define the keys. The distribution is taken care of. For partitioning, you have to define and maintain pretty much everything to get it to work. There's even more to it, but you get the core idea. These are different processes and mechanisms that are, at the macro level, arriving at a similar end point. However, the processes these things support are very different. The distribution assists in increased performance while partitioning is primarily a means of improved data management (rolling windows, etc.). These are very different things with different intents even as they are similar.
© 2022 - 2024 — McMap. All rights reserved.
{kind=link}