Short answer:
1. Assign colors to variables with color_discrete_map :
color_discrete_map = {'virginica': 'blue', 'setosa': 'red', 'versicolor': 'green'}
or:
2. Manage the order of your data to enable the correct color cycle with:
order_df(df_input = df, order_by='species', order=['virginica', 'setosa', 'versicolor'])
... where order_df is a function that handles the ordering of long dataframes for which you'll find the complete definition in the code snippets below.
The details:
color_discrete_map = {'virginica': 'blue', 'setosa': 'red', 'versicolor': 'green'}
The downside is that you'll have to specify variable names and colors. And that quickly becomes tedious if you're working with dataframes where the number of variables is not fixed. In which case it would be much more convenient to follow the default color sequence or specify one to your liking. So I would rather consider managing the order of your dataset so that you'll get the desired colormatching.
2. The source of the real challenge:
px.Scatter() will assign color to variable in the order they appear in your dataframe. Here you're using two different sourcesdf and df[df.species.isin(['virginica', 'setosa', 'versicolor'])] (let's name the latter df2). Running df2['species'].unique() will give you:
array(['setosa', 'virginica'], dtype=object)
And running df['species'] will give you:
array(['setosa', 'versicolor', 'virginica'], dtype=object)
See that versicolor pops up in the middle? Thats's why red is no longer assigned to 'virginica', but 'versicolor' instead.
Suggested solution:
So in order to build a complete solution, you'd have to find a way to specify the order of the variables in the source dataframe. Thats very straight forward for a column with unique values. It's a bit more work for a dataframe of a long format such as this. You could do it as described in the post Changing row order in pandas dataframe without losing or messing up data. But below I've put together a very easy function that takes care of both the subset and the order of the dataframe you'd like to plot with plotly express.
Using the complete code and switching between the lines under # data subsets will give you the three following plots:
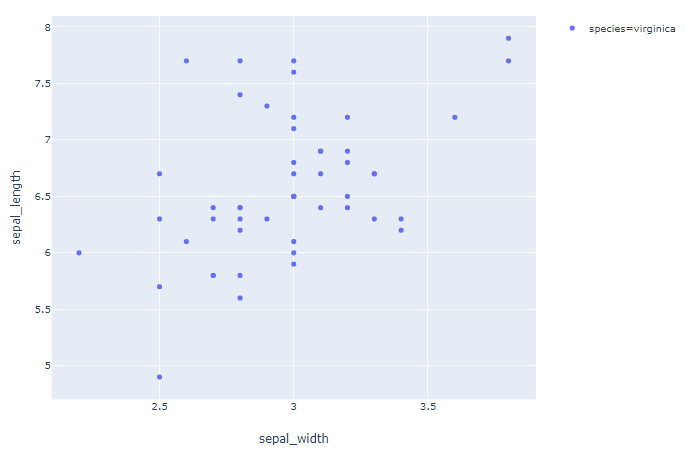
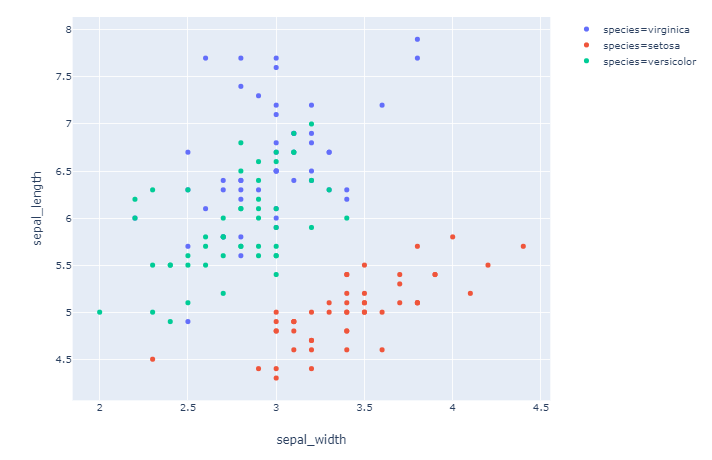
Plot 1: order=['virginica']
![enter image description here]()
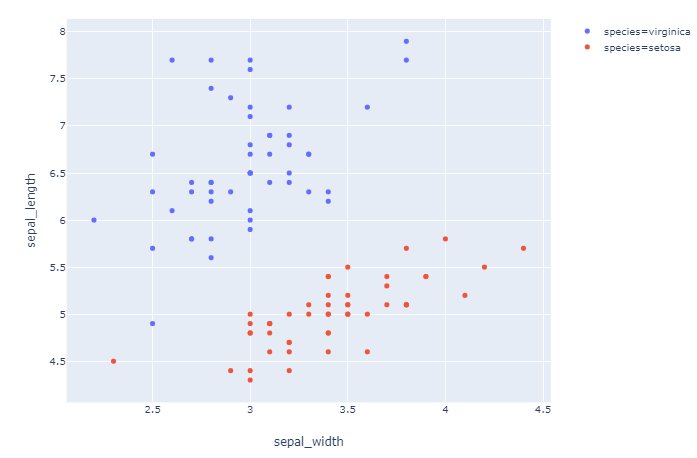
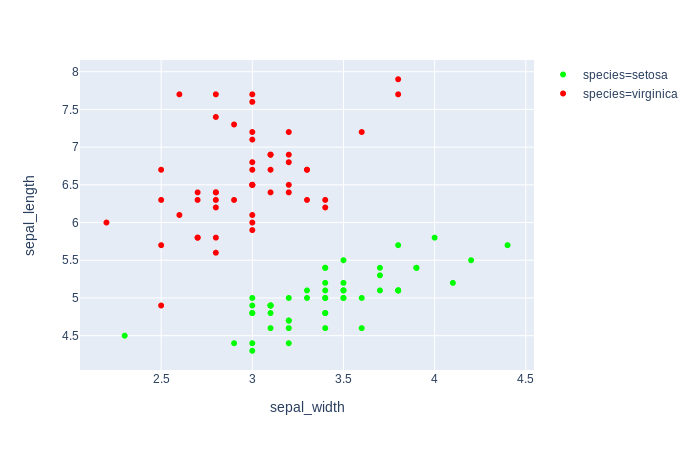
Plot 2: ['virginica', 'setosa']
![enter image description here]()
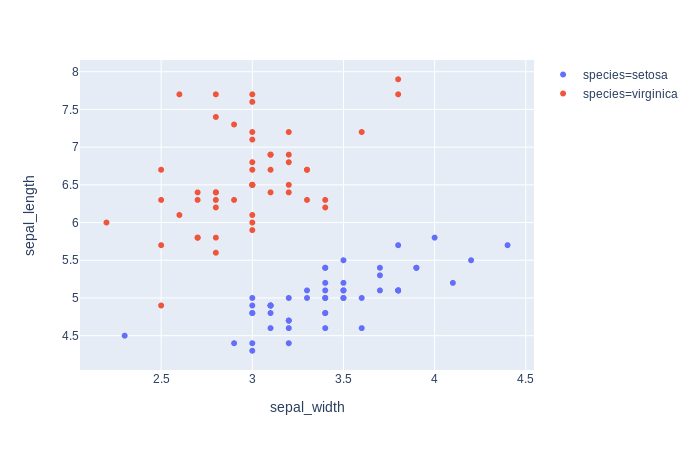
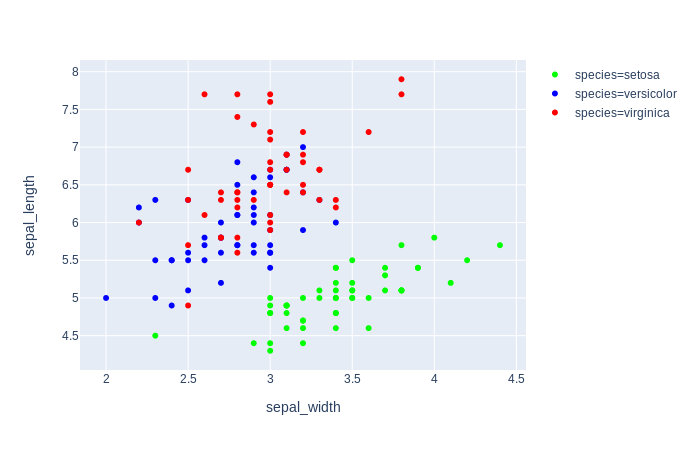
Plot 3: order=['virginica', 'setosa', 'versicolor']
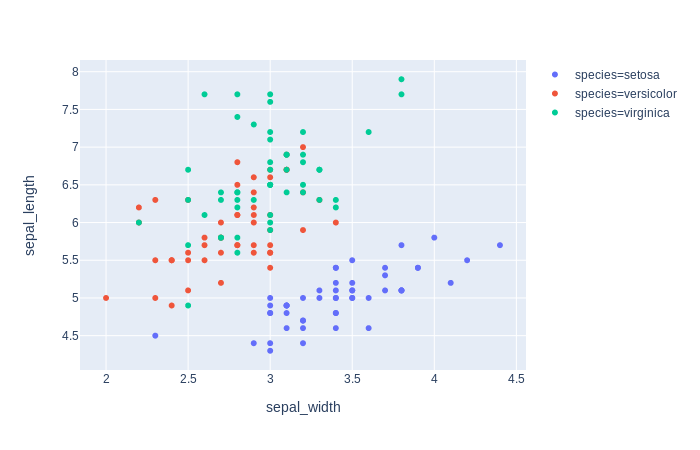
![enter image description here]()
Complete code:
# imports
import pandas as pd
import plotly.express as px
# data
df = px.data.iris()
# function to subset and order a pandas
# dataframe fo a long format
def order_df(df_input, order_by, order):
df_output=pd.DataFrame()
for var in order:
df_append=df_input[df_input[order_by]==var].copy()
df_output = pd.concat([df_output, df_append])
return(df_output)
# data subsets
df_express = order_df(df_input = df, order_by='species', order=['virginica'])
df_express = order_df(df_input = df, order_by='species', order=['virginica', 'setosa'])
df_express = order_df(df_input = df, order_by='species', order=['virginica', 'setosa', 'versicolor'])
# plotly
fig = px.scatter(df_express, x="sepal_width", y="sepal_length", color="species")
fig.show()