I decided to continue Fast corners optimisation and stucked at
_mm_movemask_epi8 SSE instruction. How can i rewrite it for ARM Neon with uint8x16_t input?
SSE _mm_movemask_epi8 equivalent method for ARM NEON
after some tests it looks like following code works correct:
int32_t _mm_movemask_epi8_neon(uint8x16_t input)
{
const int8_t __attribute__ ((aligned (16))) xr[8] = {-7,-6,-5,-4,-3,-2,-1,0};
uint8x8_t mask_and = vdup_n_u8(0x80);
int8x8_t mask_shift = vld1_s8(xr);
uint8x8_t lo = vget_low_u8(input);
uint8x8_t hi = vget_high_u8(input);
lo = vand_u8(lo, mask_and);
lo = vshl_u8(lo, mask_shift);
hi = vand_u8(hi, mask_and);
hi = vshl_u8(hi, mask_shift);
lo = vpadd_u8(lo,lo);
lo = vpadd_u8(lo,lo);
lo = vpadd_u8(lo,lo);
hi = vpadd_u8(hi,hi);
hi = vpadd_u8(hi,hi);
hi = vpadd_u8(hi,hi);
return ((hi[0] << 8) | (lo[0] & 0xFF));
}
I know this post is quite outdated but I found it useful to give my (validated) solution. It assumes all ones/all zeroes in every lane of the Input argument.
const uint8_t __attribute__ ((aligned (16))) _Powers[16]=
{ 1, 2, 4, 8, 16, 32, 64, 128, 1, 2, 4, 8, 16, 32, 64, 128 };
// Set the powers of 2 (do it once for all, if applicable)
uint8x16_t Powers= vld1q_u8(_Powers);
// Compute the mask from the input
uint64x2_t Mask= vpaddlq_u32(vpaddlq_u16(vpaddlq_u8(vandq_u8(Input, Powers))));
// Get the resulting bytes
uint16_t Output;
vst1q_lane_u8((uint8_t*)&Output + 0, (uint8x16_t)Mask, 0);
vst1q_lane_u8((uint8_t*)&Output + 1, (uint8x16_t)Mask, 8);
(Mind http://gcc.gnu.org/bugzilla/show_bug.cgi?id=47553, anyway.)
Similarly to Michael, the trick is to form the powers of the indexes of the non-null entries, and to sum them pairwise three times. This must be done with increasing data size to double the stride on every addition. You reduce from 2 x 8 8-bit entries to 2 x 4 16-bit, then 2 x 2 32-bit and 2 x 1 64-bit. The low byte of these two numbers gives the solution. I don't think there is an easy way to pack them together to form a single short value using NEON.
Takes 6 NEON instructions if the input is in the suitable form and the powers can be preloaded.
Do most ARM chips hit a store-forwarding stall if this compiles to 2 byte stores and one half-word reload? Can't a vector shuffle put the low byte of each half of a 128-bit register into the low 2 bytes of that register? If you're on 32-bit ARM, that means the bytes you want are at the bottom of two
d registers that compose one q register, so can you zip them together to get the 2 bytes you want at the bottom of one d register? Compilers would probably do a bad job if you did this with intrinsics, though. –
Alluvium Thanks a lot for the answer, very helpful. I replaced the last two lines with Output = (uint16_t)(vst1q_lane_u64(Mask, 0) + (vst1q_lane_u64(Mask, 0) << 8)); That seems to be much faster and doesn't assume little endianness (well, for those extra rare cases of big endian NEONs). –
Benevolence
Sorry, vgetq_lane_u64(), obviously. –
Benevolence
@David, tried your solution replacing the last two lines (using
vgetq_lane_u64) and the output seems to be incorrect –
Paulenepauletta @mwag, Thank you, I don't really remember this exact details and unfortunately I could not find it in the code that used it because I ended up ditching this approach all together and solving my specific issue in a completely different way. You are probably right, thank you for warning others as well :) –
Benevolence
The obvious solution seems to be completely missed here.
// Use shifts to collect all of the sign bits.
// I'm not sure if this works on big endian, but big endian NEON is very
// rare.
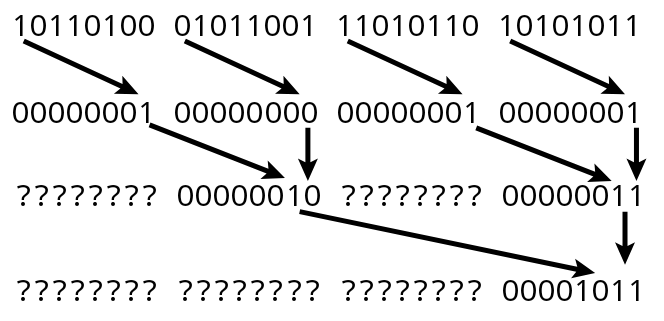
int vmovmaskq_u8(uint8x16_t input)
{
// Example input (half scale):
// 0x89 FF 1D C0 00 10 99 33
// Shift out everything but the sign bits
// 0x01 01 00 01 00 00 01 00
uint16x8_t high_bits = vreinterpretq_u16_u8(vshrq_n_u8(input, 7));
// Merge the even lanes together with vsra. The '??' bytes are garbage.
// vsri could also be used, but it is slightly slower on aarch64.
// 0x??03 ??02 ??00 ??01
uint32x4_t paired16 = vreinterpretq_u32_u16(
vsraq_n_u16(high_bits, high_bits, 7));
// Repeat with wider lanes.
// 0x??????0B ??????04
uint64x2_t paired32 = vreinterpretq_u64_u32(
vsraq_n_u32(paired16, paired16, 14));
// 0x??????????????4B
uint8x16_t paired64 = vreinterpretq_u8_u64(
vsraq_n_u64(paired32, paired32, 28));
// Extract the low 8 bits from each lane and join.
// 0x4B
return vgetq_lane_u8(paired64, 0) | ((int)vgetq_lane_u8(paired64, 8) << 8);
}
Interesting. Compiles for ARM and AArch64: godbolt.org/z/-UfPYD. I don't know what
vsra does, though, and this answer doesn't explain it. I assume it's a right-shift and accumulate. –
Alluvium Correct. Shifts right and adds. Here is a diagram of the operation in binary. –
Dx
{kind=link}
This question deserves a newer answer for aarch64. The addition of new capabilities to Armv8 allows the same function to be implemented in fewer instructions. Here's my version:
uint32_t _mm_movemask_aarch64(uint8x16_t input)
{
const uint8_t __attribute__ ((aligned (16))) ucShift[] = {-7,-6,-5,-4,-3,-2,-1,0,-7,-6,-5,-4,-3,-2,-1,0};
uint8x16_t vshift = vld1q_u8(ucShift);
uint8x16_t vmask = vandq_u8(input, vdupq_n_u8(0x80));
uint32_t out;
vmask = vshlq_u8(vmask, vshift);
out = vaddv_u8(vget_low_u8(vmask));
out += (vaddv_u8(vget_high_u8(vmask)) << 8);
return out;
}
after some tests it looks like following code works correct:
int32_t _mm_movemask_epi8_neon(uint8x16_t input)
{
const int8_t __attribute__ ((aligned (16))) xr[8] = {-7,-6,-5,-4,-3,-2,-1,0};
uint8x8_t mask_and = vdup_n_u8(0x80);
int8x8_t mask_shift = vld1_s8(xr);
uint8x8_t lo = vget_low_u8(input);
uint8x8_t hi = vget_high_u8(input);
lo = vand_u8(lo, mask_and);
lo = vshl_u8(lo, mask_shift);
hi = vand_u8(hi, mask_and);
hi = vshl_u8(hi, mask_shift);
lo = vpadd_u8(lo,lo);
lo = vpadd_u8(lo,lo);
lo = vpadd_u8(lo,lo);
hi = vpadd_u8(hi,hi);
hi = vpadd_u8(hi,hi);
hi = vpadd_u8(hi,hi);
return ((hi[0] << 8) | (lo[0] & 0xFF));
}
I know this question is here for 8 years already but let me give you the answer which might solve all performance problems with emulation. It's based on the blog Bit twiddling with Arm Neon: beating SSE movemasks, counting bits and more.
Most usages of movemask instructions are coming from comparisons where the vectors have 0xFF or 0x00 values from the result of every 16 bytes. After that most cases to use movemasks are to check if none/all match, find leading/trailing or iterate over bits.
If this is the case which often is, then you can use shrn reg1, reg2, #4 instruction. This instruction called Shift-Right-then-Narrow instruction can reduce a 128-bit byte mask to a 64-bit nibble mask (by alternating low and high nibbles to the result). This allows the mask to be extracted to a 64-bit general purpose register.
const uint16x8_t equalMask = vreinterpretq_u16_u8(vceqq_u8(chunk, vdupq_n_u8(tag)));
const uint8x8_t res = vshrn_n_u16(equalMask, 4);
const uint64_t matches = vget_lane_u64(vreinterpret_u64_u8(res), 0);
return matches;
After that you can use all bit operations you typically use on x86 with very minor tweaks like shifting by 2 or doing a scalar AND.

This is only useful on AArch64. –
Express
Note that I haven't tested any of this, but something like this might work:
X := the vector that you want to create the mask from
A := 0x808080808080...
B := 0x00FFFEFDFCFB... (i.e. 0,-1,-2,-3,...)
X = vand_u8(X, A); // Keep d7 of each byte in X
X = vshl_u8(X, B); // X[7]>>=0; X[6]>>=1; X[5]>>=2; ...
// Each byte of X now contains its msb shifted 7-N bits to the right, where N
// is the byte index.
// Do 3 pairwise adds in order to pack all these into X[0]
X = vpadd_u8(X, X);
X = vpadd_u8(X, X);
X = vpadd_u8(X, X);
// X[0] should now contain the mask. Clear the remaining bytes if necessary
This would need to be repeated once to process a 128-bit vector, since vpadd only works on 64-bit vectors.
hi @Impenitent thanx for the example. can u please explain how can i fill vector B with required bytes? for A i can use vdup_n_u8(0x80) but how should i do it for A? also u u write vshl_u8 but in comment there is shift right? –
Bluster
To initialize vector B:
vld1 from a const array(?). About the right shift: the ARM documentation states "If the shift value is positive, the operation is a left shift. Otherwise, it is a right shift.". I'm not entirely sure if that's the case if the data you shift is u8, or if you need to use s8. –
Impenitent yep i understand that i need to load B from an array i was just wondering about supplied values in that vector. can u be more specific about it? should be just [0,-1,-2,-3,-4,-5,-6,-7]? and yes i need it for u8 data vector at the moment –
Bluster
Yes, 0..-7. Another possibility would be to replace the
vand/vshl with a vcge (where you compare against vector A) followed by a vand where you AND against 0x8040201008040201. –
Impenitent © 2022 - 2024 — McMap. All rights reserved.
movmskpsinstead ofpmovmskb. – Alluvium