I have a spark job where i am doing outer join between two data frames . Size of first data frame is 260 GB,file format is text files which is split into 2200 files and the size of second data frame is 2GB . Then writing data frame output which is about 260 GB into S3 takes very long time is more than 2 hours after that i cancelled because i have been changed heavily on EMR .
Here is my cluster info .
emr-5.9.0
Master: m3.2xlarge
Core: r4.16xlarge 10 machines (each machine has 64 vCore, 488 GiB memory,EBS Storage:100 GiB)
This is my cluster config that i am setting
capacity-scheduler yarn.scheduler.capacity.resource-calculator :org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
emrfs-site fs.s3.maxConnections: 200
spark maximizeResourceAllocation: true
spark-defaults spark.dynamicAllocation.enabled: true
I tried setting memory component manually also like below and the performance was better but same thing it was taking again very long time
--num-executors 60--conf spark.yarn.executor.memoryOverhead=9216 --executor-memory 72G --conf spark.yarn.driver.memoryOverhead=3072 --driver-memory 26G --executor-cores 10 --driver-cores 3 --conf spark.default.parallelism=1200
I am not using default partition to save data into S3 .
Adding all details about the jobs and query plan so that it will be easy to understand .
The real reason is partition .And that is taking most of the time. Because i have 2K files so if i use re partition like 200 the output files comes in lakhs and then loading again in spark is not a good story .
In below image i dont know why sort is again called after project
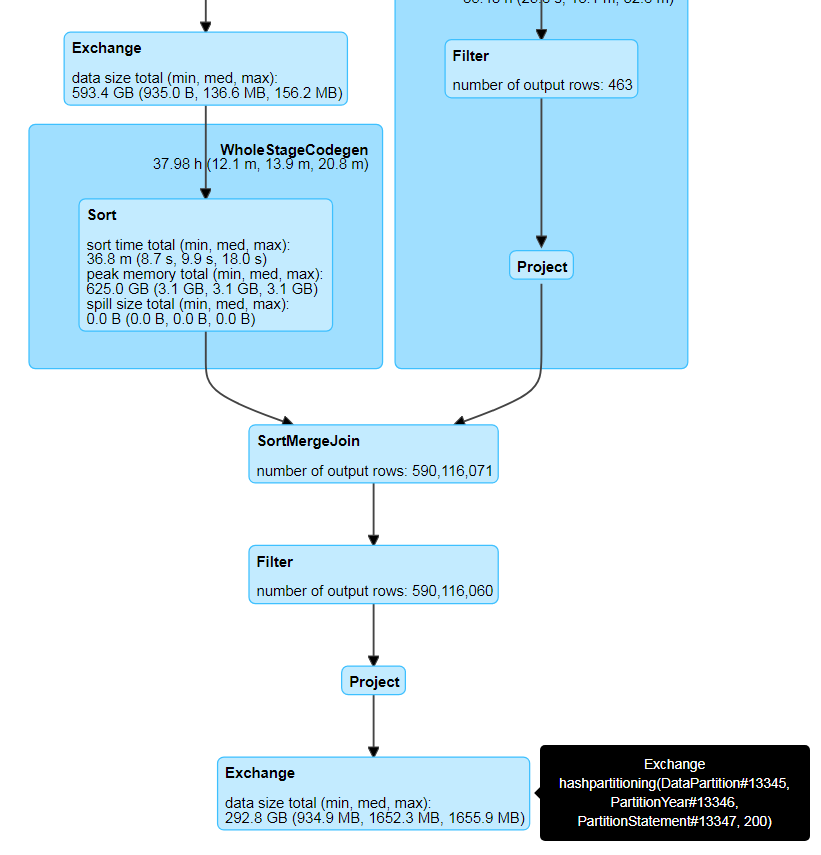
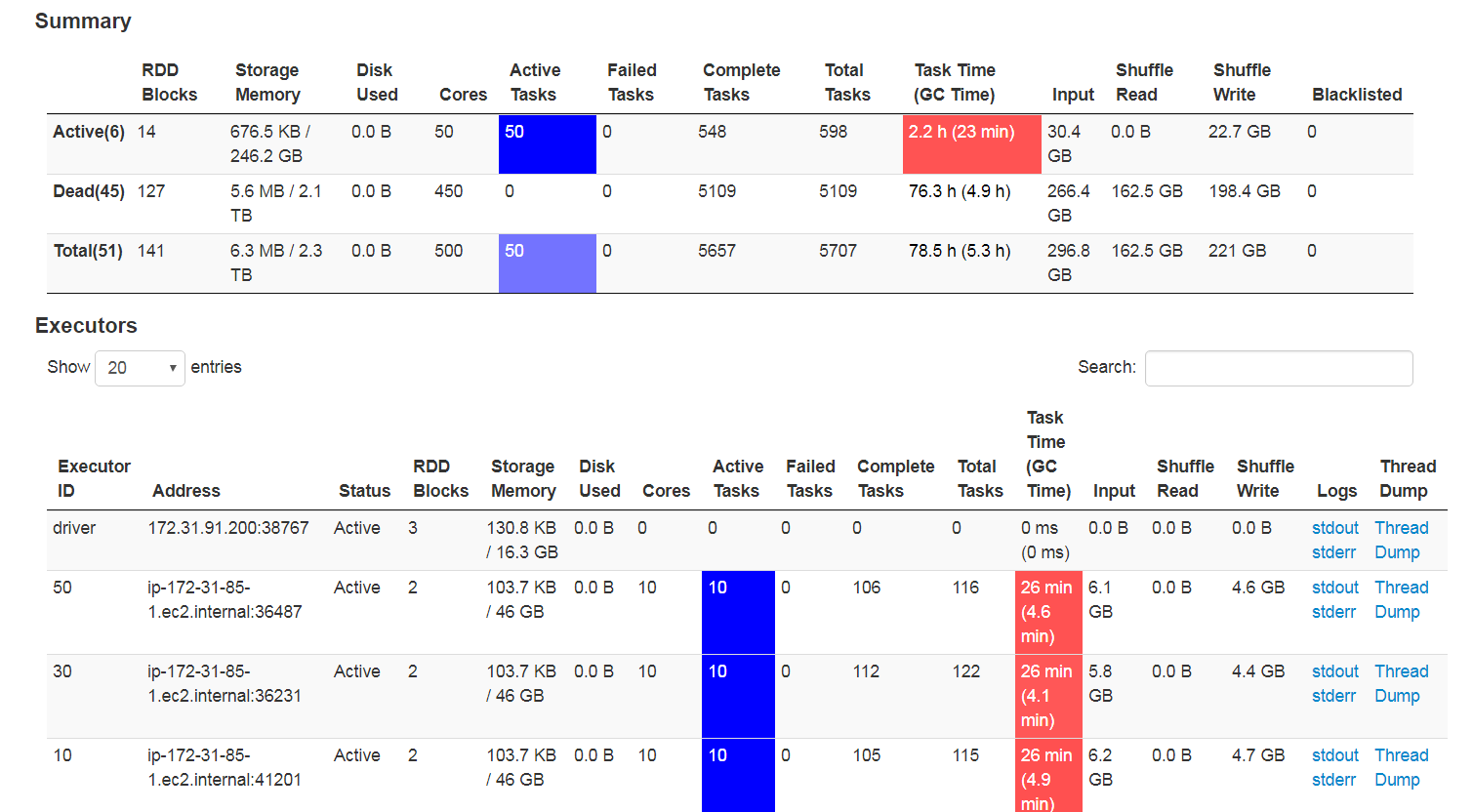
In below Image GC is too high for me ..Do oi have to handle this please suggest how?
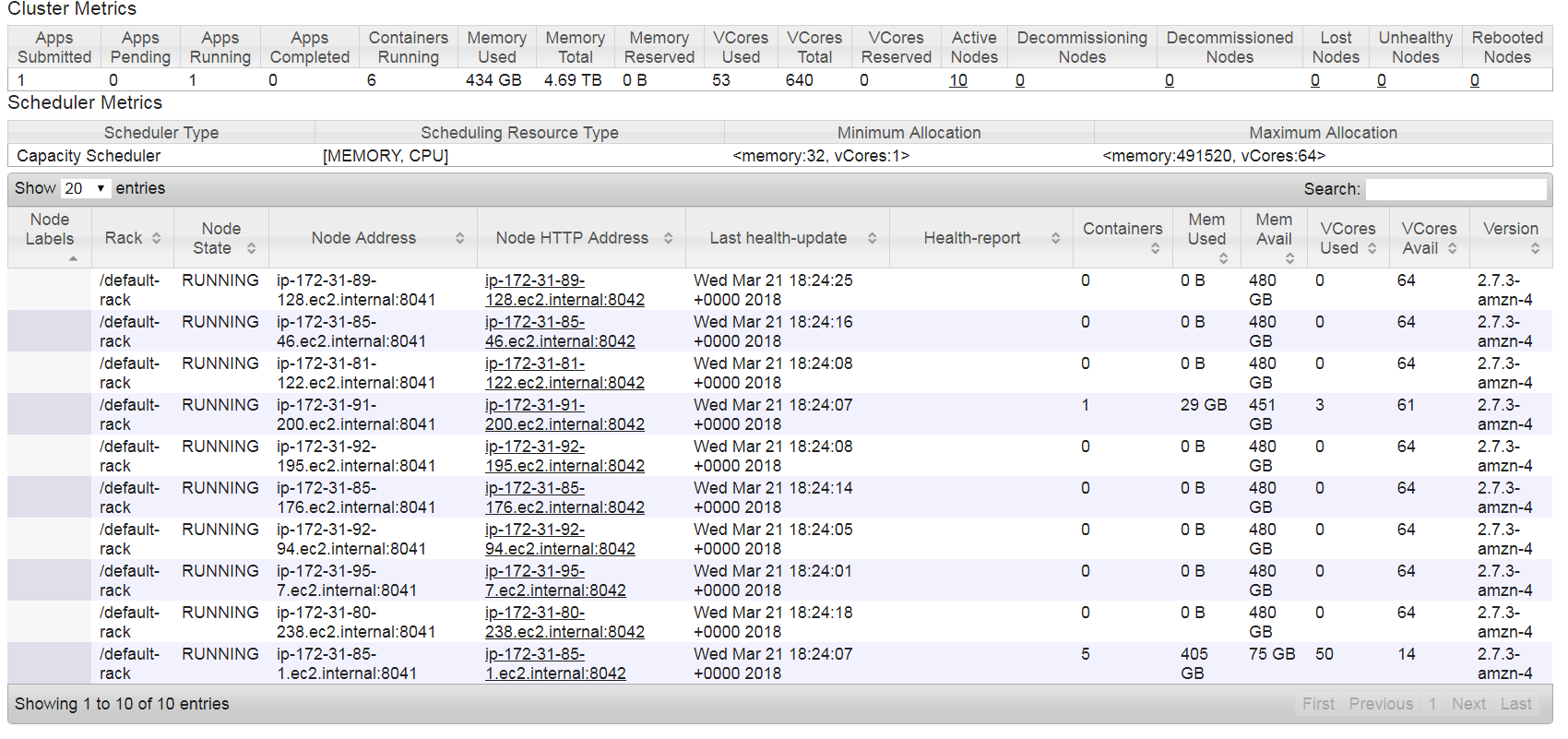
Below is nodes health status .t this point data is getting saved into S3 no wonder why i can see only two nodes are active and all are idle .
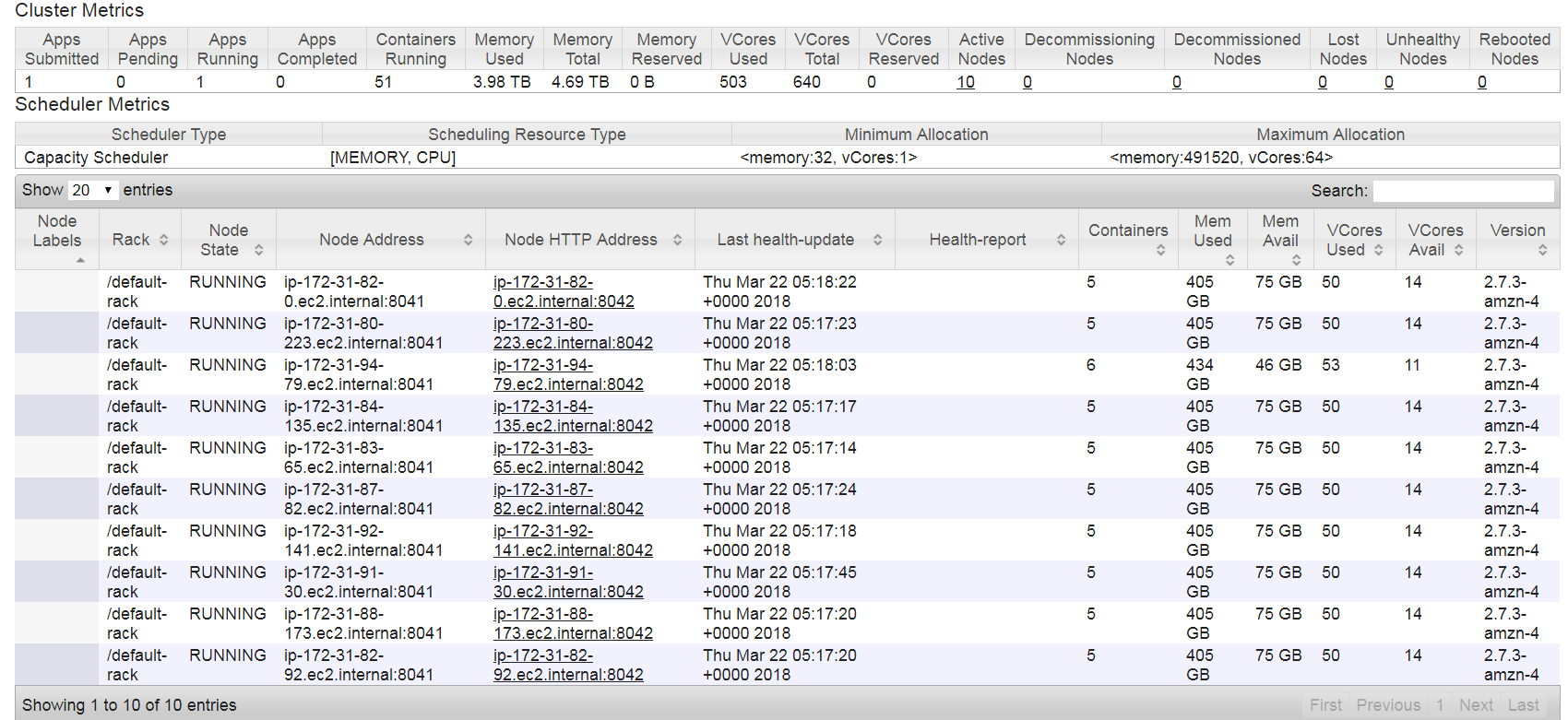
This is the cluster details when it is loading ..At this point i can see cluster is fully utilized but while saving data into S3 many nodes are free .
Finally here is my code where i perform Join and then save into S3...
import org.apache.spark.sql.expressions._
val windowSpec = Window.partitionBy("uniqueFundamentalSet", "PeriodId", "SourceId", "StatementTypeCode", "StatementCurrencyId", "FinancialStatementLineItem_lineItemId").orderBy(unix_timestamp($"TimeStamp", "yyyy-MM-dd HH:mm:ss.SSS").cast("timestamp").desc)
val latestForEachKey = df2resultTimestamp.withColumn("rank", row_number.over(windowSpec)).filter($"rank" === 1).drop("rank", "TimeStamp")
val columnMap = latestForEachKey.columns.filter(c => c.endsWith("_1") & c != "FFAction|!|_1").map(c => c -> c.dropRight(2)) :+ ("FFAction|!|_1", "FFAction|!|")
val exprs = columnMap.map(t => coalesce(col(s"${t._1}"), col(s"${t._2}")).as(s"${t._2}"))
val exprsExtended = Array(col("uniqueFundamentalSet"), col("PeriodId"), col("SourceId"), col("StatementTypeCode"), col("StatementCurrencyId"), col("FinancialStatementLineItem_lineItemId")) ++ exprs
//Joining both dara frame here
val dfMainOutput = (dataMain.join(latestForEachKey, Seq("uniqueFundamentalSet", "PeriodId", "SourceId", "StatementTypeCode", "StatementCurrencyId", "FinancialStatementLineItem_lineItemId"), "outer") select (exprsExtended: _*)).filter(!$"FFAction|!|".contains("D|!|"))
//Joing ends here
val dfMainOutputFinal = dfMainOutput.na.fill("").select($"DataPartition", $"PartitionYear", $"PartitionStatement", concat_ws("|^|", dfMainOutput.schema.fieldNames.filter(_ != "DataPartition").filter(_ != "PartitionYear").filter(_ != "PartitionStatement").map(c => col(c)): _*).as("concatenated"))
val headerColumn = dataHeader.columns.toSeq
val headerFinal = headerColumn.mkString("", "|^|", "|!|").dropRight(3)
val dfMainOutputFinalWithoutNull = dfMainOutputFinal.withColumn("concatenated", regexp_replace(col("concatenated"), "|^|null", "")).withColumnRenamed("concatenated", headerFinal)
// dfMainOutputFinalWithoutNull.repartition($"DataPartition", $"PartitionYear", $"PartitionStatement")
.write
.partitionBy("DataPartition", "PartitionYear", "PartitionStatement")
.format("csv")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.option("nullValue", "")
.option("delimiter", "\t")
.option("quote", "\u0000")
.option("header", "true")
.option("codec", "bzip2")
.save(outputFileURL)