I am trying to implement my own LRU cache. Yes, I know that Java provides a LinkedHashMap for this purpose, but I am trying to implement it using basic data structures.
From reading about this topic, I understand that I need a HashMap for O(1) lookup of a key and a linked list for management of the "least recently used" eviction policy. I found these references that all use a standard library hashmap but implement their own linked list:
- "What data structures are commonly used for LRU caches and quickly locating objects?" (stackoverflow.com)
- "What is the best way to Implement a LRU Cache?" (quora.com)
- "Implement a LRU Cache in C++" (uml.edu)
- "LRU Cache (Java)" (programcreek.com)
The hash table is supposed to directly store a linked list Node as I show below. My cache should store Integer keys and String values.
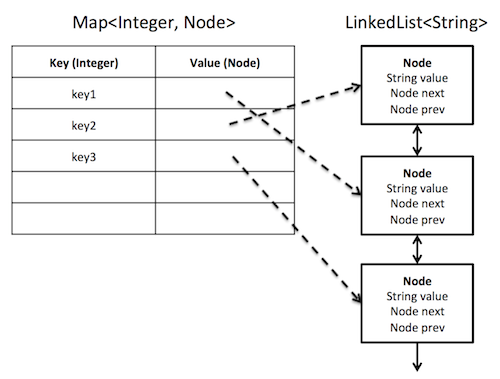
However, in Java the LinkedList collection does not expose its internal nodes, so I can't store them inside the HashMap. I could instead have the HashMap store indices into the LinkedList, but then getting to an item would require O(N) time. So I tried to store a ListIterator instead.
import java.util.Map;
import java.util.HashMap;
import java.util.List;
import java.util.LinkedList;
import java.util.ListIterator;
public class LRUCache {
private static final int DEFAULT_MAX_CAPACITY = 10;
protected Map<Integer, ListIterator> _map = new HashMap<Integer, ListIterator>();
protected LinkedList<String> _list = new LinkedList<String>();
protected int _size = 0;
protected int _maxCapacity = 0;
public LRUCache(int maxCapacity) {
_maxCapacity = maxCapacity;
}
// Put the key, value pair into the LRU cache.
// The value is placed at the head of the linked list.
public void put(int key, String value) {
// Check to see if the key is already in the cache.
ListIterator iter = _map.get(key);
if (iter != null) {
// Key already exists, so remove it from the list.
iter.remove(); // Problem 1: ConcurrentModificationException!
}
// Add the new value to the front of the list.
_list.addFirst(value);
_map.put(key, _list.listIterator(0));
_size++;
// Check if we have exceeded the capacity.
if (_size > _maxCapacity) {
// Remove the least recently used item from the tail of the list.
_list.removeLast();
}
}
// Get the value associated with the key.
// Move value to the head of the linked list.
public String get(int key) {
String result = null;
ListIterator iter = _map.get(key);
if (iter != null) {
//result = iter
// Problem 2: HOW DO I GET THE STRING FROM THE ITERATOR?
}
return result;
}
public static void main(String argv[]) throws Exception {
LRUCache lruCache = new LRUCache(10);
lruCache.put(10, "This");
lruCache.put(20, "is");
lruCache.put(30, "a");
lruCache.put(40, "test");
lruCache.put(30, "some"); // Causes ConcurrentModificationException
}
}
So this leads to three problems:
Problem 1: I am getting a ConcurrentModificationException when I update the LinkedList using the iterator that I store in the HashMap.
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.LinkedList$ListItr.checkForComodification(LinkedList.java:953)
at java.util.LinkedList$ListItr.remove(LinkedList.java:919)
at LRUCache.put(LRUCache.java:31)
at LRUCache.main(LRUCache.java:71)
Problem 2. How do I retrieve the value pointed to by the ListIterator? It seems I can only retrieve the next() value.
Problem 3. Is there any way to implement this LRU cache using the Java collections LinkedList, or do I really have to implement my own linked list?