Description
We have a Spark Streaming 1.5.2 application in Scala that reads JSON events from a Kinesis Stream, does some transformations/aggregations and writes the results to different S3 prefixes. The current batch interval is 60 seconds. We have 3000-7000 events/sec. We’re using checkpointing to protect us from losing aggregations.
It’s been working well for a while, recovering from exceptions and even cluster restarts. We recently recompiled the code for Spark Streaming 1.6.0, only changing the library dependencies in the build.sbt file. After running the code in a Spark 1.6.0 cluster for several hours, we’ve noticed the following:
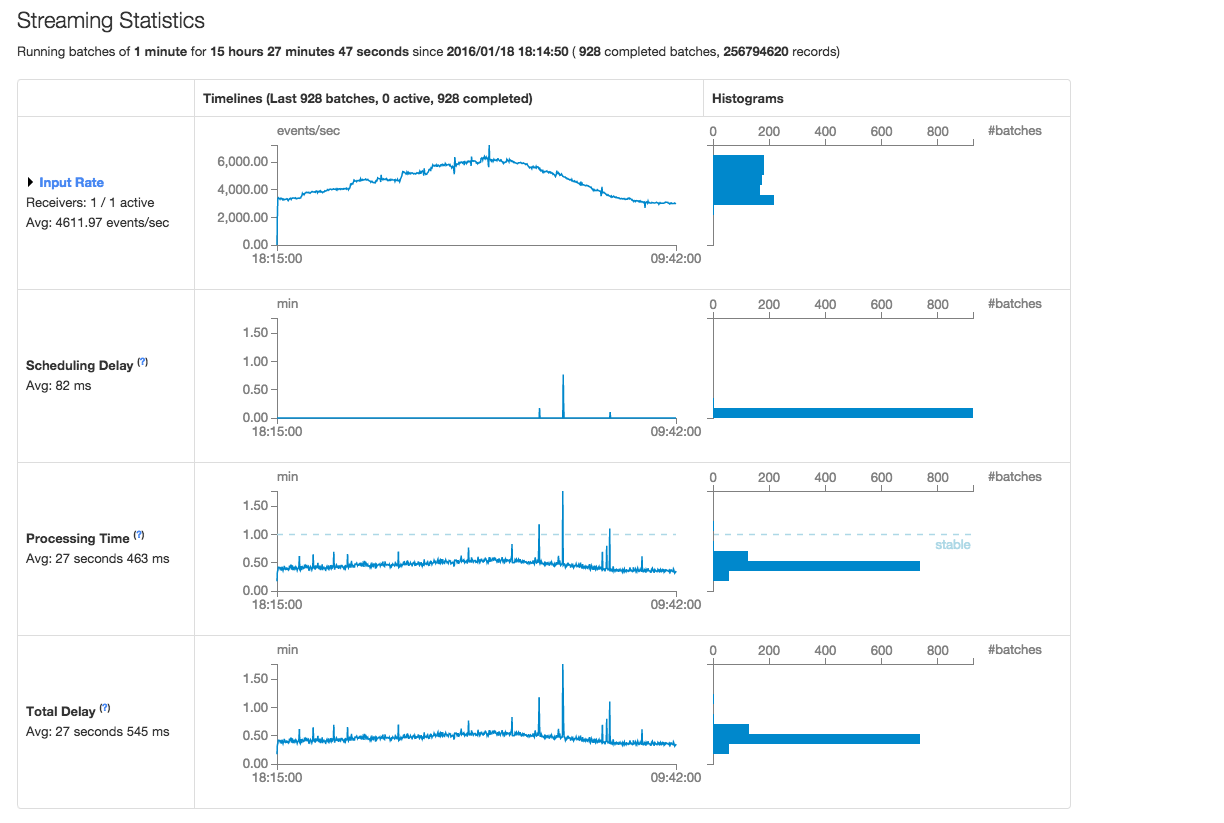
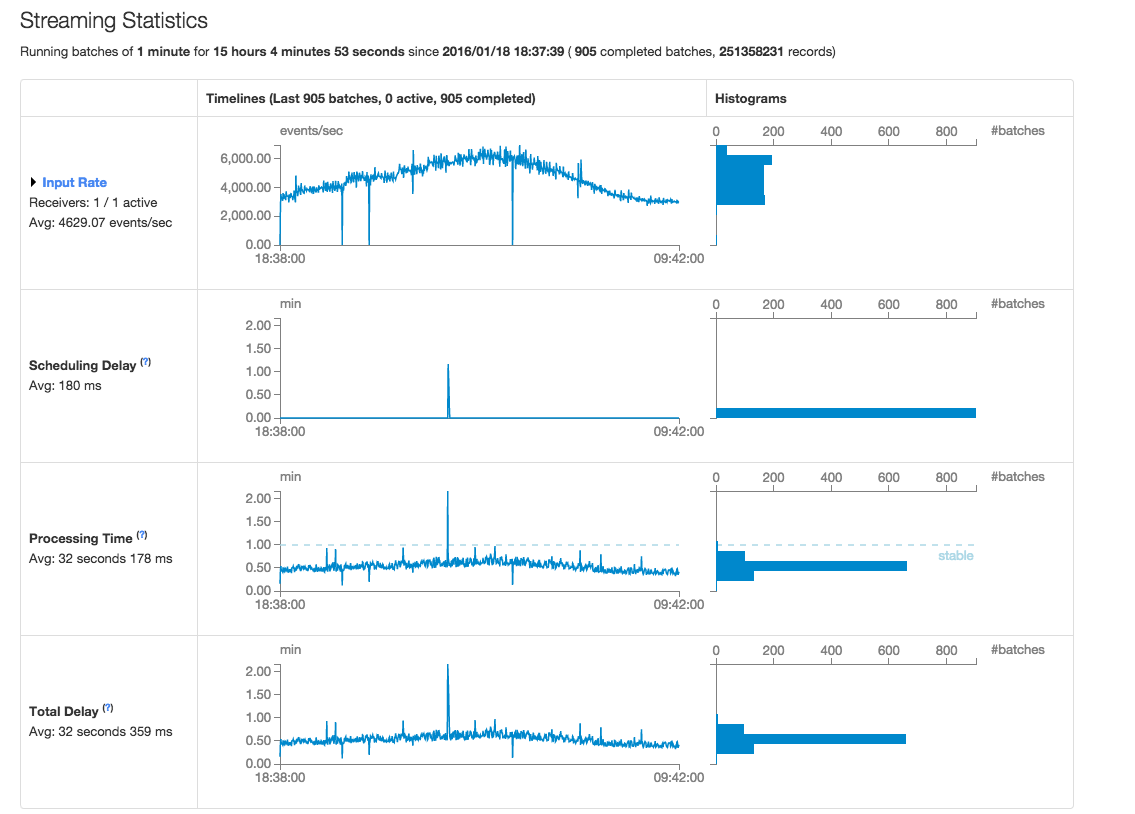
- “Input Rate” and “Processing Time” volatility has increased substantially (see the screenshots below) in 1.6.0.
- Every few hours, there’s an ‘’Exception thrown while writing record: BlockAdditionEvent … to the WriteAheadLog. java.util.concurrent.TimeoutException: Futures timed out after [5000 milliseconds]” exception (see complete stack trace below) coinciding with the drop to 0 events/sec for specific batches (minutes).
After doing some digging, I think the second issue looks related to this Pull Request. The initial goal of the PR: “When using S3 as a directory for WALs, the writes take too long. The driver gets very easily bottlenecked when multiple receivers send AddBlock events to the ReceiverTracker. This PR adds batching of events in the ReceivedBlockTracker so that receivers don’t get blocked by the driver for too long.”
We are checkpointing in S3 in Spark 1.5.2 and there are no performance/reliability issues. We’ve tested checkpointing in Spark 1.6.0 in S3 and local NAS and in both cases we’re receiving this exception. It looks like when it takes more than 5 seconds to checkpoint a batch, this exception arises and we’ve checked that the events for that batch are lost forever.
Questions
Is the increase in “Input Rate” and “Processing Time” volatility expected in Spark Streaming 1.6.0 and is there any known way of improving it?
Do you know of any workaround apart from these 2?:
1) To guarantee that it takes less than 5 seconds for the checkpointing sink to write all files. In my experience, you cannot guarantee that with S3, even for small batches. For local NAS, it depends on who’s in charge of infrastructure (difficult with cloud providers).
2) Increase the spark.streaming.driver.writeAheadLog.batchingTimeout property value.
Would you expect to lose any events in the described scenario? I'd think that if batch checkpointing fails, the shard/receiver Sequence Numbers wouldn't be increased and it would be retried at a later time.
Spark 1.5.2 Statistics - Screenshot
Spark 1.6.0 Statistics - Screenshot
Full Stack Trace
16/01/19 03:25:03 WARN ReceivedBlockTracker: Exception thrown while writing record: BlockAdditionEvent(ReceivedBlockInfo(0,Some(3521),Some(SequenceNumberRanges(SequenceNumberRange(StreamEventsPRD,shardId-000000000003,49558087746891612304997255299934807015508295035511636018,49558087746891612304997255303224294170679701088606617650), SequenceNumberRange(StreamEventsPRD,shardId-000000000004,49558087949939897337618579003482122196174788079896232002,49558087949939897337618579006984380295598368799020023874), SequenceNumberRange(StreamEventsPRD,shardId-000000000001,49558087735072217349776025034858012188384702720257294354,49558087735072217349776025038332464993957147037082320914), SequenceNumberRange(StreamEventsPRD,shardId-000000000009,49558088270111696152922722880993488801473174525649617042,49558088270111696152922722884455852348849472550727581842), SequenceNumberRange(StreamEventsPRD,shardId-000000000000,49558087841379869711171505550483827793283335010434154498,49558087841379869711171505554030816148032657077741551618), SequenceNumberRange(StreamEventsPRD,shardId-000000000002,49558087853556076589569225785774419228345486684446523426,49558087853556076589569225789389107428993227916817989666))),BlockManagerBasedStoreResult(input-0-1453142312126,Some(3521)))) to the WriteAheadLog.
java.util.concurrent.TimeoutException: Futures timed out after [5000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53)
at scala.concurrent.Await$.result(package.scala:107)
at org.apache.spark.streaming.util.BatchedWriteAheadLog.write(BatchedWriteAheadLog.scala:81)
at org.apache.spark.streaming.scheduler.ReceivedBlockTracker.writeToLog(ReceivedBlockTracker.scala:232)
at org.apache.spark.streaming.scheduler.ReceivedBlockTracker.addBlock(ReceivedBlockTracker.scala:87)
at org.apache.spark.streaming.scheduler.ReceiverTracker.org$apache$spark$streaming$scheduler$ReceiverTracker$$addBlock(ReceiverTracker.scala:321)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverTrackerEndpoint$$anonfun$receiveAndReply$1$$anon$1$$anonfun$run$1.apply$mcV$sp(ReceiverTracker.scala:500)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1230)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverTrackerEndpoint$$anonfun$receiveAndReply$1$$anon$1.run(ReceiverTracker.scala:498)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Source Code Extract
...
// Function to create a new StreamingContext and set it up
def setupContext(): StreamingContext = {
...
// Create a StreamingContext
val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
// Create a Kinesis DStream
val data = KinesisUtils.createStream(ssc,
kinesisAppName, kinesisStreamName,
kinesisEndpointUrl, RegionUtils.getRegionByEndpoint(kinesisEndpointUrl).getName(),
InitialPositionInStream.LATEST, Seconds(kinesisCheckpointIntervalSeconds),
StorageLevel.MEMORY_AND_DISK_SER_2, awsAccessKeyId, awsSecretKey)
...
ssc.checkpoint(checkpointDir)
ssc
}
// Get or create a streaming context.
val ssc = StreamingContext.getActiveOrCreate(checkpointDir, setupContext)
ssc.start()
ssc.awaitTermination()