I'm using Gensim Doc2Vec model, trying to cluster portions of a customer support conversations. My goal is to give the support team an auto response suggestions.
Figure 1: shows a sample conversations where the user question is answered in the next conversation line, making it easy to extract the data:
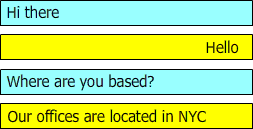
during the conversation "hello" and "Our offices are located in NYC" should be suggested
Figure 2: describes a conversation where the questions and answers are not in sync
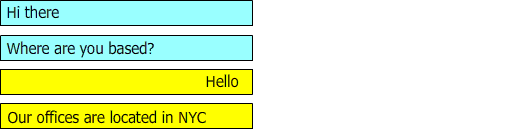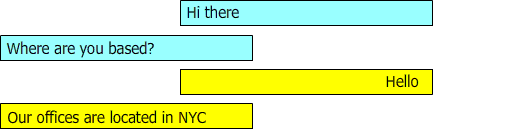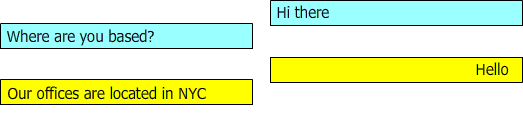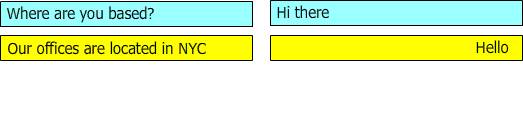
during the conversation "hello" and "Our offices are located in NYC" should be suggested
Figure 3: describes a conversation where the context for the answer is built over time, and for classification purpose (I'm assuming) some of the lines are redundant.

during the conversation "here is a link for the free trial account" should be suggested
I have the following data per conversation line (simplified):
who wrote the line (user or agent), text, time stamp
I'm using the following code to train my model:
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedLineDocument
import datetime
print('Creating documents',datetime.datetime.now().time())
context = TaggedLineDocument('./test_data/context.csv')
print('Building model',datetime.datetime.now().time())
model = Doc2Vec(context,size = 200, window = 10, min_count = 10, workers=4)
print('Training...',datetime.datetime.now().time())
for epoch in range(10):
print('Run number :',epoch)
model.train(context)
model.save('./test_data/model')
Q: How should I structure my training data and what heuristics could be applied in order to extract it from the raw data?