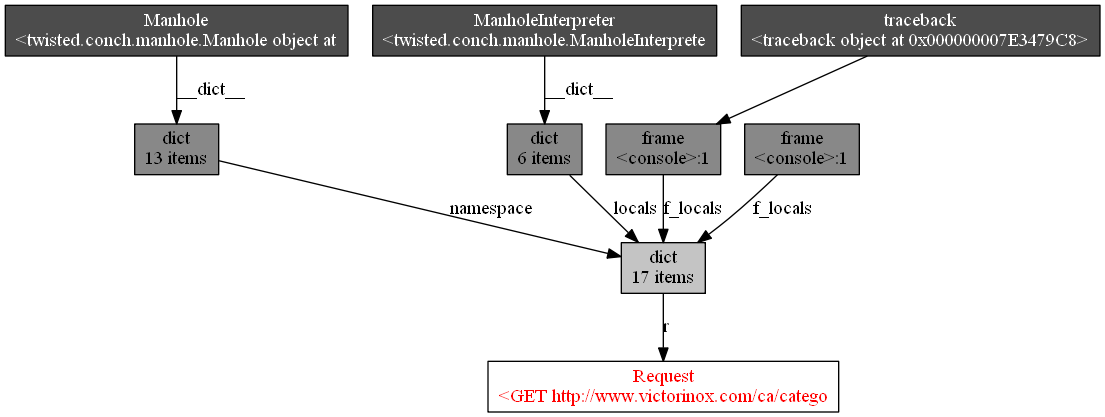
My spider have a serious memory leak.. After 15 min of run its memory 5gb and scrapy tells (using prefs() ) that there 900k requests objects and thats all. What can be the reason for this high number of living requests objects? Request only goes up and doesnt goes down. All other objects are close to zero.
My spider looks like this:
class ExternalLinkSpider(CrawlSpider):
name = 'external_link_spider'
allowed_domains = ['']
start_urls = ['']
rules = (Rule(LxmlLinkExtractor(allow=()), callback='parse_obj', follow=True),)
def parse_obj(self, response):
if not isinstance(response, HtmlResponse):
return
for link in LxmlLinkExtractor(allow=(), deny=self.allowed_domains).extract_links(response):
if not link.nofollow:
yield LinkCrawlItem(domain=link.url)
Here output of prefs()
HtmlResponse 2 oldest: 0s ago
ExternalLinkSpider 1 oldest: 3285s ago
LinkCrawlItem 2 oldest: 0s ago
Request 1663405 oldest: 3284s ago
Memory for 100k scraped pages can hit 40gb mark on some sites ( for example at victorinox.com it reach 35gb of memory at 100k scraped pages mark). On other its much lesser.
UPD.