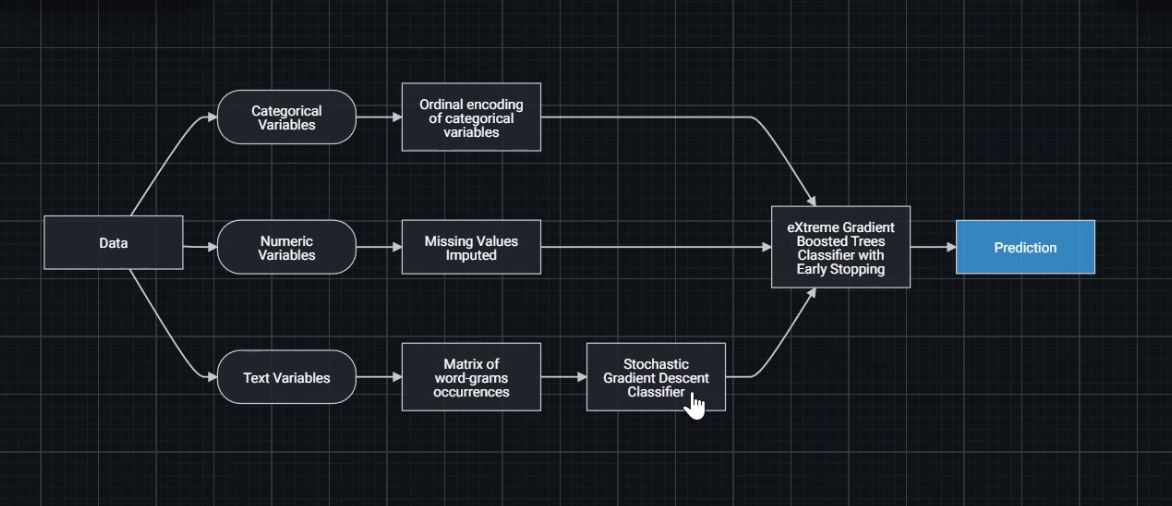
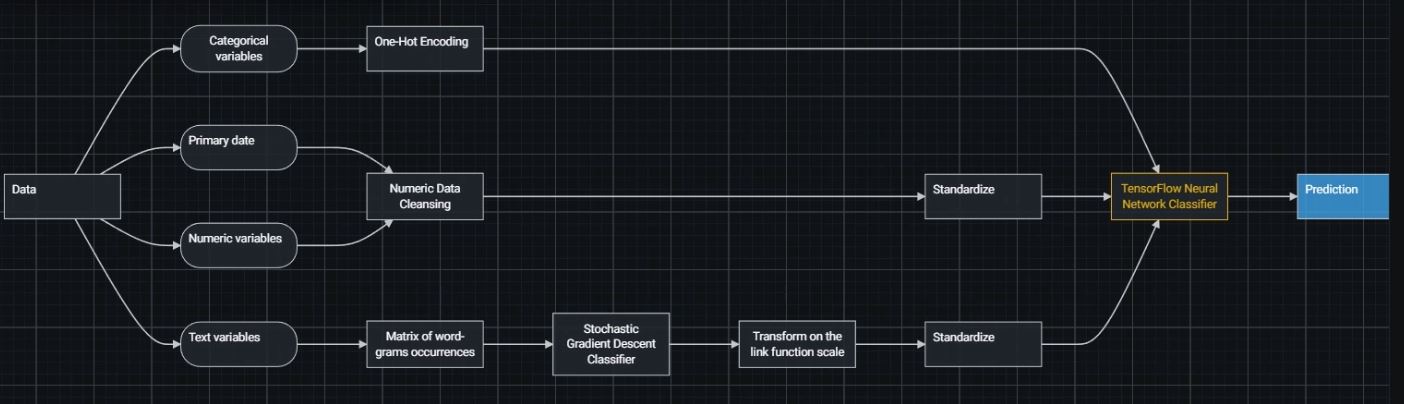
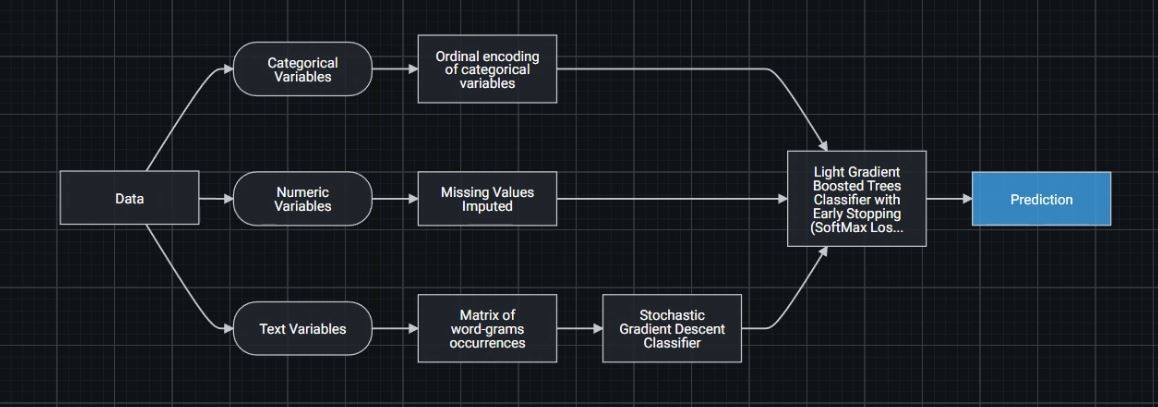
I have a classic NLP problem, I have to classify a news as fake or real.
I have created two sets of features:
A) Bigram Term Frequency-Inverse Document Frequency
B) Approximately 20 Features associated to each document obtained using pattern.en (https://www.clips.uantwerpen.be/pages/pattern-en) as subjectivity of the text, polarity, #stopwords, #verbs, #subject, relations grammaticals etc ...
Which is the best way to combine the TFIDF features with the other features for a single prediction? Thanks a lot to everyone.