I have read a lot of posts and watched several Youtube videos C++ atomic and memory model (ConCpp 17, 14).
When I read the book Concurrency In Action, section 5.3.3, RELAXED ORDERING, I still cannot understand the example provided by the author under his assumptions.
Assumptions by the author
It’s not just that the compiler can reorder the instructions. Even if the threads are running the same bit of code, they can disagree on the order of events because of operations in other threads in the absence of explicit ordering constraints, because the different CPU caches and internal buffers can hold different values for the same memory. It’s so important I’ll say it again: threads don’t have to agree on the order of events. Not only do you have to throw out mental models based on interleaving operations, you also have to throw out mental models based on the idea of the compiler or processor reordering the instructions.
Suppose that the code we see is not reordered.
The example code:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_relaxed); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 3
if(x.load(std::memory_order_relaxed)) // 4
++z;
}
int main() {
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 5
}
from this link: https://www.developerfusion.com/article/138018/memory-ordering-for-atomic-operations-in-c0x/

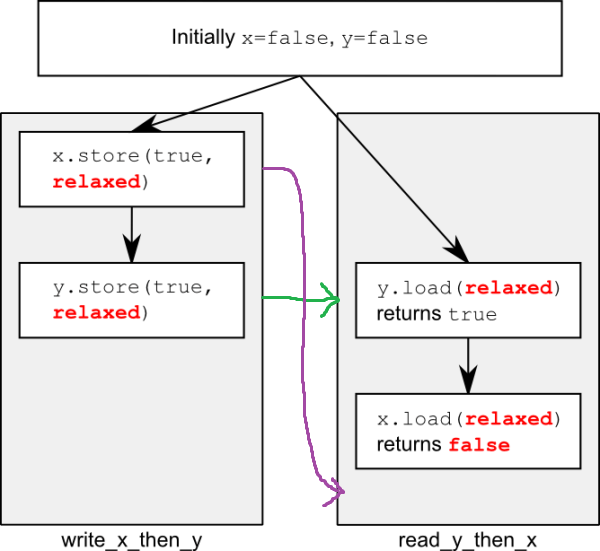
Why x.load(relaxed) return false but y.load(relaxed) return true?
The conclusion by the author
This time the assert (5) can fire, because the load of x (4) can read false, even though the load of y (3) reads true and the store of x (1) happens-before the store of y (2). x and y are different variables, so there are no ordering guarantees relating to the visibility of values arising from operations on each.
Q. Why load of x can be false?
The author concludes that assert can fire. So, z can be 0.
So, if(x.load(std::memory_order_relaxed)) : x.load(std::memory_order_relaxed) is false.
But anyway, while(!y.load(std::memory_order_relaxed)); makes y true.
If we don't reorder the code sequence of (1) and (2), how is it possible that y is true but x is still not be stored?
How to understand the figure provided by the author?
Based on the store of x (1) happens-before the store of y (2), if x.store(relaxed) happen-before y.store(relaxed), x should be true now. But why x is still false even y is true?
y.store(...), and thenx.store(...)so that thread b can derive that conclusion. According to "there are no synchronization or ordering constraints imposed on other reads or writes, only this operation's atomicity is guaranteed" and the reasoning of the example provided here: en.cppreference.com/w/cpp/atomic/memory_order#Relaxed_ordering – Kaule