Is it possible to trigger an AWS Glue crawler on new files, that get uploaded into a S3 bucket, given that the crawler is "pointed" to that bucket? In other words: a file upload generates an event, that causes AWS Glue crawler to analyse it. I know that there is schedule based crawling, but never found an event- based one.
Event based trigger of AWS Glue Crawler after a file is uploaded into a S3 Bucket?
Asked Answered
No, there is currently no direct way to invoke an AWS Glue crawler in response to an upload to an S3 bucket. S3 event notifications can only be sent to:
- SNS
- SQS
- Lambda
However, it would be trivial to write a small piece of Lambda code to programmatically invoke a Glue crawler using the relevant language SDK.
could you please elaborate on where to find useful tutorials / code snippets to invoke a glue crawler with Lambda? –
Zena
Each language SDK should support Glue. You can call startCrawler() from JavaScript, for example: docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Glue.html –
Hernandez
As a quick start, here is a blow-by-blow account of how to create a Lambda in Python to do this. This is the first time I've created a Lambda so YMMV.
- To save time, select 'Create function' and then click 'Blueprints'. Select the sample called 's3-get-object-python' and click 'Configure'
- Fill in the Lambda name and create a new Role unless you already have one.
- The wizard will setup the S3 trigger at the same time
- Once you create it, you will need to find the Role that it created and add a new permission via a policy containing:
"Action": "glue:StartCrawler", "Resource": "*"
- Change the code to something like:
from __future__ import print_function
import json
import boto3
print('Loading function')
glue = boto3.client(service_name='glue', region_name='ap-southeast-2',
endpoint_url='https://glue.ap-southeast-2.amazonaws.com')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
try:
glue.start_crawler(Name='my-glue-crawler')
except Exception as e:
print(e)
print('Error starting crawler')
raise e
Finally, assuming you selected that the trigger should be disabled while developing, click the S3 trigger from the designer panel and ensure it is enabled (you may need to save the lambda after making this change)
That's it, but note that an exception will be thrown if the crawler is already running so you will want to handle that if you have frequent uploads or long crawls. See: https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-crawler-crawling.html#aws-glue-api-crawler-crawling-StartCrawler
Edit:
This helped me with the handling of exceptions (from AWS Glue): https://github.com/boto/boto3/issues/1606#issuecomment-401423567
No, there is currently no direct way to invoke an AWS Glue crawler in response to an upload to an S3 bucket. S3 event notifications can only be sent to:
- SNS
- SQS
- Lambda
However, it would be trivial to write a small piece of Lambda code to programmatically invoke a Glue crawler using the relevant language SDK.
could you please elaborate on where to find useful tutorials / code snippets to invoke a glue crawler with Lambda? –
Zena
Each language SDK should support Glue. You can call startCrawler() from JavaScript, for example: docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Glue.html –
Hernandez
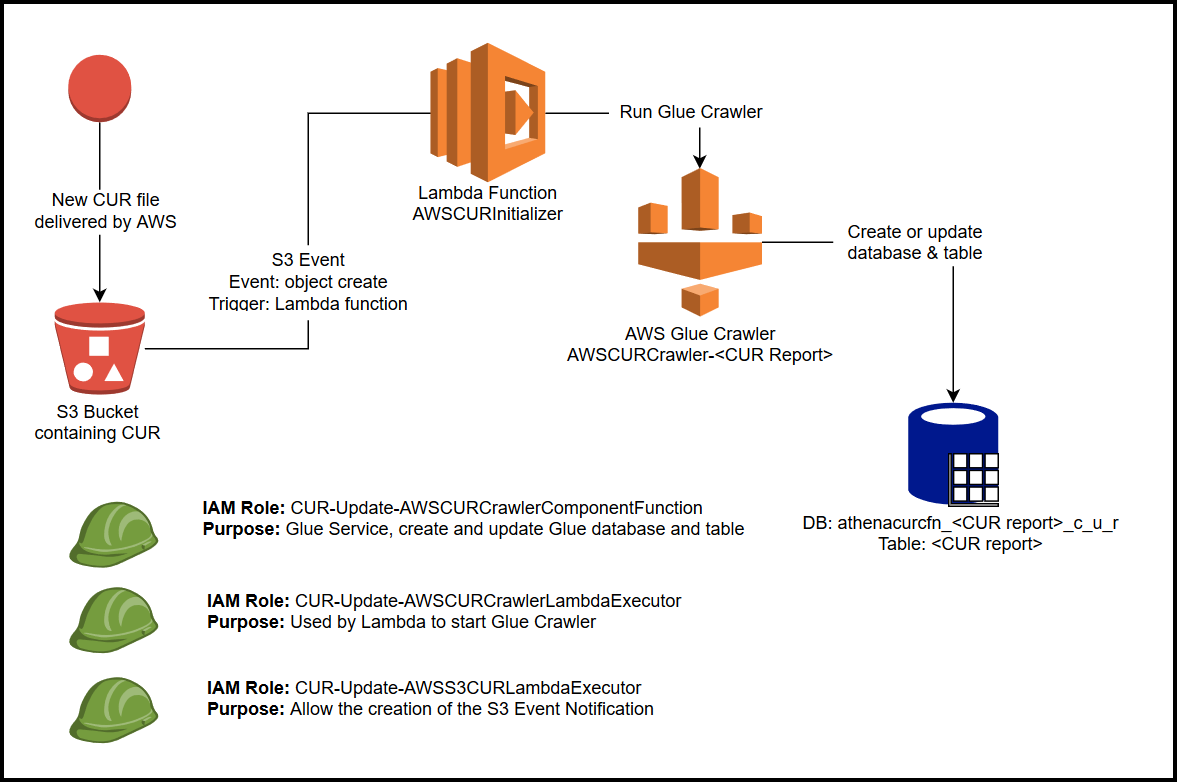 Here is a step-by-step guide(link below) for a similar architecture. (Refer the above picture for the architecture)
Here is a step-by-step guide(link below) for a similar architecture. (Refer the above picture for the architecture)
Thanks for this. What do you use to do your flow diagram? Is that a tool in AWS or some other tool? –
Shiism
I use Draw.io in browser –
Afc
Ensure that
- events for the S3 bucket of interest are logged to AWS CloudTrail and EventBridge.
- the EventBridge role to invoke targets has the following policy attached:
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"glue:notifyEvent"
],
"Resource":[
"<arn_your_workflow>"
]
}
]
}
an EventBridge rule targeting the workflow with a following eventpattern has been set up:
{ "source": ["aws.s3"], "detail-type": ["AWS API Call via CloudTrail"], "detail": { "eventSource": ["s3.amazonaws.com"], "eventName": ["PutObject"], "requestParameters": { "bucketName": ["<bucket-name>"] } }}
Then you can set up a trigger to start the crawler. Define your conditions in EventBatchingCondition and fill in the rest. Here the crawler starts either after 1 file or 300 seconds:
{
"Name": "<TRIGGER_NAME>",
"WorkflowName": "<WORKFLOW_NAME>",
"Type": "EVENT",
"EventBatchingCondition": {
"BatchSize": 1,
"BatchWindow": 300
},
"Actions": [
{
"CrawlerName": "<CRAWLER_NAME>"
}
]
}
Save it as a json file e.g. create-trigger.json, then in cli run
aws glue create-trigger --cli-input-json file://create-trigger-crawler.json
Read more:
© 2022 - 2024 — McMap. All rights reserved.