If you want to have have multiple layers that pass the information backward or forward in time, there are two ways how to design this. Assume the forward layer consists of two layers F1, F2 and the backword layer consists of two layers B1, B2.
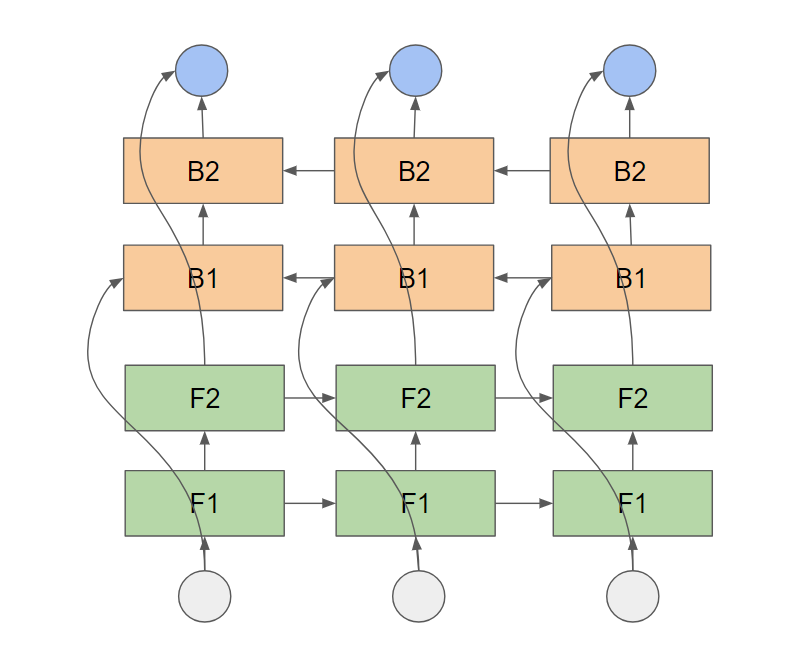
If you use tf.nn.bidirectional_dynamic_rnn the model will look like this (time flows from left to right):
![enter image description here]()
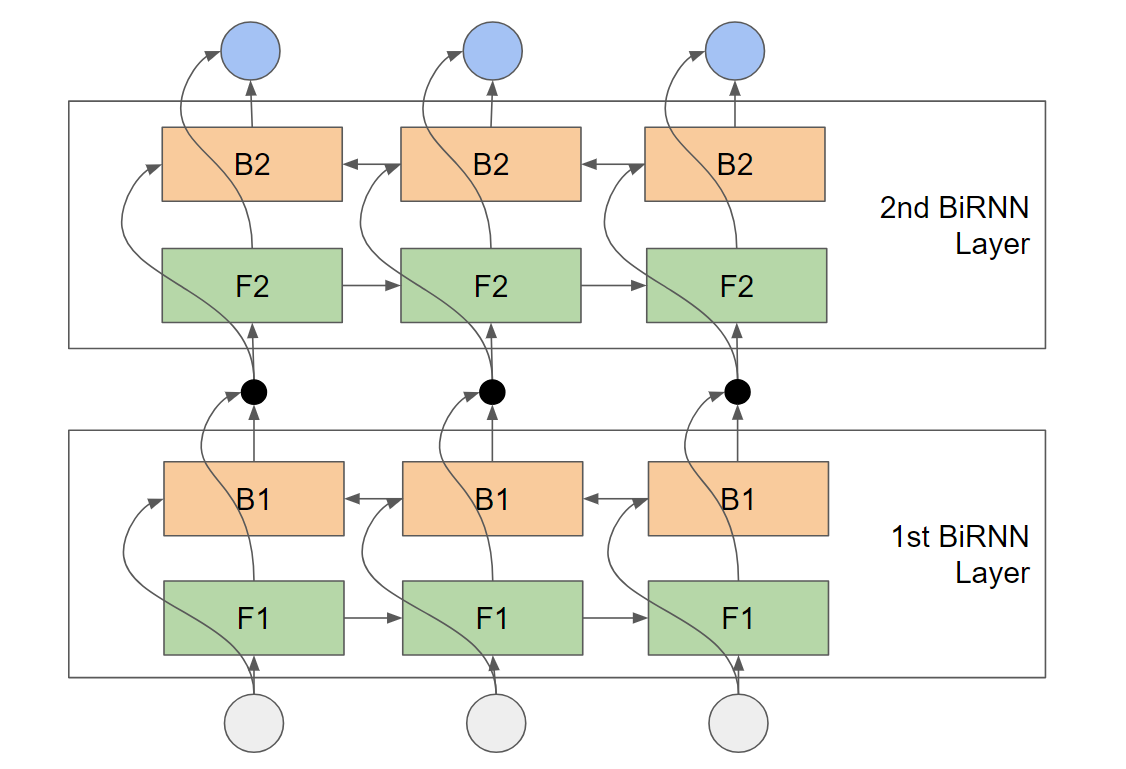
If you use tf.contrib.rnn.stack_bidirectional_dynamic_rnn the model will look like this:
![enter image description here]()
Here the black dot between first and second layer represents a concatentation. I.e., the outputs of the forward and backward cells are concatenated together and fed to the backward and forward layers of the next upper layer. This means both F2 and B2 receive exactly the same input and there is an explicit connection between backward and forward layers. In "Speech Recognition with Deep Recurrent Neural Networks" Graves et al. summarize this as follows:
... every hidden layer receives input from both the
forward and backward layers at the level below.
This connection only happens implicitly in the unstacked BiRNN (first image), namely when mapping back to the output. The stacked BiRNN usually performed better for my purposes, but I guess that depends on your problem setting. But for sure it is worthwile to try it out!
EDIT
In response to your comment: I base my answer on the documentation of the function tf.contrib.rnn.stack_bidirectional_dynamic_rnn which says:
Stacks several bidirectional rnn layers. The combined forward and
backward layer outputs are used as input of the next layer.
tf.bidirectional_rnn does not allow to share forward and backward
information between layers.
Also, I looked at the implementation available under this link.
Difference between bidirectional_dynamic_rnn and stack_bidirectional_dynamic_rnn in Tensorflow– Sumatra