I am using SQL Server 2014. I am currently trying to combine millions of personnel application records in to a single personnel record.
The records contain the following columns:
ID, First_Name, Last_Name, DOB, Post_Code, Mobile, Email
A person can enter their details numerous times but due to fat fingers or fraud they can sometimes put in, incorrect details.
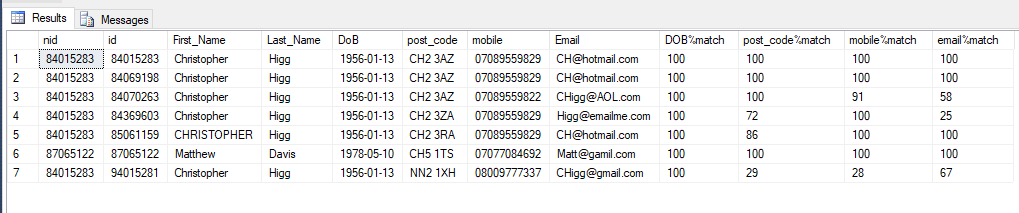
In my example Christopher has filled his details in 5 times, First_Name, Last_Name, DOB are always correct, Post_Code, Mobile and Email contain various connotations.
What I want to do is take the min(id) associated with this group in this case 84015283 and put it in to a new table, this will be the primary key and then you will see the other id's that are associated with it.
Examples
NID CID
------------------
84015283 84015283
84015283 84069198
84015283 84070263
84015283 84369603
84015283 85061159
Where it gets a little complicated is, where 2 different people can have the same First_Name, Last_Name and DOB, at least one of the other fields must match "post_code, mobile or email" as per my example to another record within the group.
Though first_name, last_name, DoB match between ID's 84015283, 84069198, 84070263. 84015283, 84069198 are identical so they would match without an issue, 84070263 matches on the postcode, 84369603 matches on the mobile to a previous record and 85061159 matches on a previous mobile/email but not post_code.
If putting the NID within the original dataset is easier I can go with this rather than putting it all in a separate table.
After some googling and trying to get my head around this, I believe that using "Merge" might be a good way to achieve what I am after but I am concerned it will take a very long time due to the number of records involved.
Also going forward any routine would have to be run on subsequent new records.
I have listed the code for the example if anyone can help
DROP TABLE customer_dist
CREATE TABLE [dbo].customer_dist
(
[id] [int] NOT NULL,
[First_Name] [varchar](50) NULL,
[Last_Name] [varchar](50) NULL,
[DoB] [date] NULL,
[post_code] [varchar](50) NULL,
[mobile] [varchar](50) NULL,
[Email] [varchar](100) NULL,
)
INSERT INTO customer_dist (id, First_Name, Last_Name, DoB, post_code, mobile, Email)
VALUES ('84015283', 'Christopher', 'Higg', '1956-01-13', 'CH2 3AZ', '07089559829', '[email protected]'),
('84069198', 'Christopher', 'Higg', '1956-01-13', 'CH2 3AZ', '07089559829', '[email protected]'),
('84070263', 'Christopher', 'Higg', '1956-01-13', 'CH2 3AZ', '07089559822', '[email protected]'),
('84369603', 'Christopher', 'Higg', '1956-01-13', 'CH2 3ZA', '07089559829', '[email protected]'),
('85061159', 'CHRISTOPHER', 'Higg', '1956-01-13', 'CH2 3RA', '07089559829', '[email protected]'),
('87065122', 'Matthew', 'Davis', '1978-05-10', 'CH5 1TS', '07077084692', '[email protected]')
SELECT * FROM customer_dist
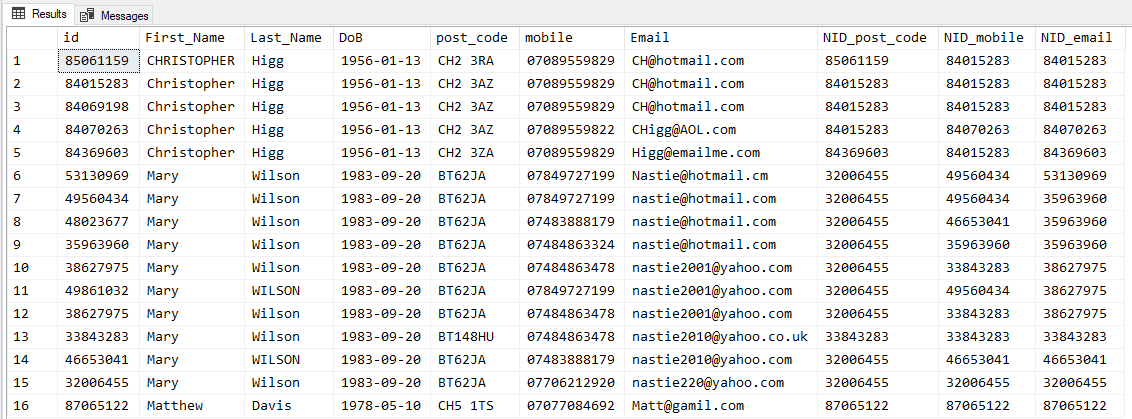
Below is the expected results, sorry I should of made it clearer what I wanted at the end.
Output Table Results
NID id First_Name Last_Name DoB post_code mobile Email
84015283 84015283 Christopher Higg 1/13/1956 CH2 3AZ 7089559829 [email protected]
84015283 84069198 Christopher Higg 1/13/1956 CH2 3AZ 7089559829 [email protected]
84015283 84070263 Christopher Higg 1/13/1956 CH2 3AZ 7089559822 [email protected]
84015283 84369603 Christopher Higg 1/13/1956 CH2 3ZA 7089559829 [email protected]
84015283 85061159 CHRISTOPHER Higg 1/13/1956 CH2 3RA 7089559829 [email protected]
78065122 87065122 Matthew Davis 05/10/1978 CH5 1TS
7077084692 [email protected]
OR
NID id
84015283 84015283
84015283 84069198
84015283 84070263
84015283 84369603
84015283 85061159
87065122 87065122
Apologies for the slow response.
I have updated my required output, I was asked to include an extra record that was not a match to the other records but did not include this in my required output.
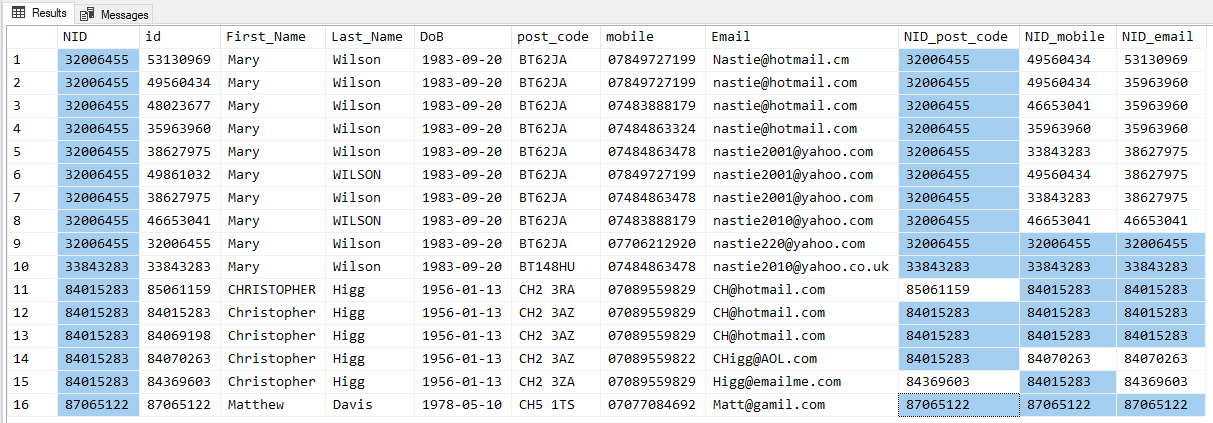
HABO's response was the closest to what was needed unfortunately on further testing with other sample data, duplicates were created and the logic broke down. Other Sample data would be :-
declare @customer_dist as Table (
[id] [int] NOT NULL,
[First_Name] [varchar](50) NULL,
[Last_Name] [varchar](50) NULL,
[DoB] [date] NULL,
[post_code] [varchar](50) NULL,
[mobile] [varchar](50) NULL,
[Email] [varchar](100) NULL );
INSERT INTO @customer_dist (id, First_Name, Last_Name, DoB, post_code, mobile, Email)
VALUES ('32006455', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07706212920', '[email protected]'),
('35963960', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07484863324', '[email protected]'),
('38627975', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07484863478', '[email protected]'),
('46653041', 'Mary', 'WILSON', '1983-09-20', 'BT62JA', '07483888179', '[email protected]'),
('48023677', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07483888179', '[email protected]'),
('49560434', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07849727199', '[email protected]'),
('49861032', 'Mary', 'WILSON', '1983-09-20', 'BT62JA', '07849727199', '[email protected]'),
('53130969', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07849727199', '[email protected]'),
('33843283', 'Mary', 'Wilson', '1983-09-20', 'BT148HU', '07484863478', '[email protected]'),
('38627975', 'Mary', 'Wilson', '1983-09-20', 'BT62JA', '07484863478', '[email protected]')
SELECT * FROM @customer_dist;

78065122 87065122 Matthew Davis? – Guanine