currently I am developing a tool for the Kinect for Windows v2 (similar to the one in XBOX ONE). I tried to follow some examples, and have a working example that shows the camera image, the depth image, and an image that maps the depth to the rgb using opencv. But I see that it duplicates my hand when doing the mapping, and I think it is due to something wrong in the coordinate mapper part.
here is an example of it:

And here is the code snippet that creates the image (rgbd image in the example)
void KinectViewer::create_rgbd(cv::Mat& depth_im, cv::Mat& rgb_im, cv::Mat& rgbd_im){
HRESULT hr = m_pCoordinateMapper->MapDepthFrameToColorSpace(cDepthWidth * cDepthHeight, (UINT16*)depth_im.data, cDepthWidth * cDepthHeight, m_pColorCoordinates);
rgbd_im = cv::Mat::zeros(depth_im.rows, depth_im.cols, CV_8UC3);
double minVal, maxVal;
cv::minMaxLoc(depth_im, &minVal, &maxVal);
for (int i=0; i < cDepthHeight; i++){
for (int j=0; j < cDepthWidth; j++){
if (depth_im.at<UINT16>(i, j) > 0 && depth_im.at<UINT16>(i, j) < maxVal * (max_z / 100) && depth_im.at<UINT16>(i, j) > maxVal * min_z /100){
double a = i * cDepthWidth + j;
ColorSpacePoint colorPoint = m_pColorCoordinates[i*cDepthWidth+j];
int colorX = (int)(floor(colorPoint.X + 0.5));
int colorY = (int)(floor(colorPoint.Y + 0.5));
if ((colorX >= 0) && (colorX < cColorWidth) && (colorY >= 0) && (colorY < cColorHeight))
{
rgbd_im.at<cv::Vec3b>(i, j) = rgb_im.at<cv::Vec3b>(colorY, colorX);
}
}
}
}
}
Does anyone have a clue of how to solve this? How to prevent this duplication?
Thanks in advance
UPDATE:
If I do a simple depth image thresholding I obtain the following image:

This is what more or less I expected to happen, and not having a duplicate hand in the background. Is there a way to prevent this duplicate hand in the background?
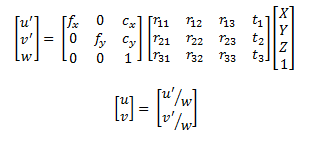
m_pCoordinateMapper->MapDepthFrameToColorSpacefunction. The other way will be doing it manually... It is important to notice that the pixels that are not "seen" by the color camera will give you, with the code above, a duplicate pixel of another place (like what I show you in the picture with the duplicate hand) – Asymptomaticmax_zandmin_zalso how them_pColorCoordinatesis initialized. I figured out that it is a type ofColorSpacePoint*but how it is declared. Also I guesscDepthWidth/HeightandcColorWidth/Heightare the dimensions of the depth and color image respectively, right? Thank you in advance. – Starksmax_zandmin_zare just some thresholding variables for the depth value, selected in the simple GUI I created.m_pColorCoordinatesI think it is the mapping between color and depth images. This code is an adaptation of one of the examples in the Kinect SDK, you can check what I did in here. It was abandoned since I had to work in other things. – Asymptomatic