Here are the steps to the current process:
- Flafka writes logs to a 'landing zone' on HDFS.
- A job, scheduled by Oozie, copies complete files from the landing zone to a staging area.
- The staging data is 'schema-ified' by a Hive table that uses the staging area as its location.
- Records from the staging table are added to a permanent Hive table (e.g.
insert into permanent_table select * from staging_table). - The data, from the Hive table, is available in Impala by executing
refresh permanent_tablein Impala.
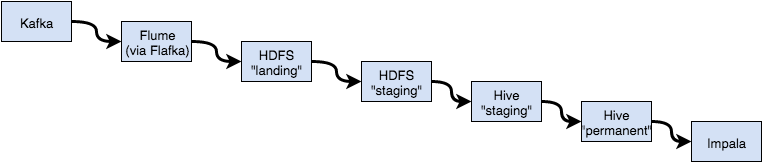
I look at the process I've built and it "smells" bad: there are too many intermediate steps that impair the flow of data.
About 20 months ago, I saw a demo where data was being streamed from an Amazon Kinesis pipe and was queryable, in near real-time, by Impala. I don't suppose they did something quite so ugly/convoluted. Is there a more efficient way to stream data from Kafka to Impala (possibly a Kafka consumer that can serialize to Parquet)?
I imagine that "streaming data to low-latency SQL" must be a fairly common use case, and so I'm interested to know how other people have solved this problem.