I have a large file which, in essence contains data like:
Netherlands,Noord-holland,Amsterdam,FooStreet,1,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,2,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,3,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,4,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,5,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,1,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,2,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,3,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,4,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,1,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,2,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,3,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,1,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,2,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,3,...,...
...
This is a multi-gigabyte file. I have a class that reads this file and exposes these lines (records) as an IEnumerable<MyObject>. This MyObject has several properties (Country,Province,City, ...) etc.
As you can see there is a LOT of duplication of data. I want to keep exposing the underlying data as an IEnumerable<MyObject>. However, some other class might (and probably will) make some hierarchical view/structure of this data like:
Netherlands
Noord-holland
Amsterdam
FooStreet [1, 2, 3, 4, 5]
BarRoad [1, 2, 3, 4]
...
Amstelveen
BazDrive [1, 2, 3]
...
...
Zuid-holland
Rotterdam
LoremAve [1, 2, 3]
...
...
...
...
When reading this file, I do, essentially, this:
foreach (line in myfile) {
fields = line.split(",");
yield return new MyObject {
Country = fields[0],
Province = fields[1],
City = fields[2],
Street = fields[3],
//...other fields
};
}
Now, to the actual question at hand: I could use string.Intern() to intern the Country, Province, City, and Street strings (those are the main 'vilains', the MyObject has several other properties not relevant to the question).
foreach (line in myfile) {
fields = line.split(",");
yield return new MyObject {
Country = string.Intern(fields[0]),
Province = string.Intern(fields[1]),
City = string.Intern(fields[2]),
Street = string.Intern(fields[3]),
//...other fields
};
}
This will save about 42% of memory (tested and measured) when holding the entire dataset in memory since all duplicate strings will be a reference to the same string. Also, when creating the hierarchical structure with a lot of LINQ's .ToDictionary() method the keys (Country, Province etc.) of the resp. dictionaries will be much more efficient.
However, one of the drawbacks (aside a slight loss of performance, which is not problem) of using string.Intern() is that the strings won't be garbage collected anymore. But when I'm done with my data I do want all that stuff garbage collected (eventually).
I could use a Dictionary<string, string> to 'intern' this data but I don't like the "overhead" of having a key and value where I am, actually, only interested in the key. I could set the value to null or the use the same string as value (which will result in the same reference in key and value). It's only a small price of a few bytes to pay, but it's still a price.
Something like a HashSet<string> makes more sense to me. However, I cannot get a reference to a string in the HashSet; I can see if the HashSet contains a specific string, but not get a reference to that specific instance of the located string in the HashSet. I could implement my own HashSet for this, but I am wondering what other solutions you kind StackOverflowers may come up with.
Requirements:
- My "FileReader" class needs to keep exposing an
IEnumerable<MyObject> - My "FileReader" class may do stuff (like
string.Intern()) to optimize memory usage - The
MyObjectclass cannot change; I won't make aCityclass,Countryclass etc. and haveMyObjectexpose those as properties instead of simplestringproperties - Goal is to be (more) memory efficient by de-duplicating most of the duplicate strings in
Country,Province,Cityetc.; how this is achieved (e.g. string interning, internal hashset / collection / structure of something) is not important. However: - I know I can stuff the data in a database or use other solutions in such direction; I am not interested in these kind of solutions.
- Speed is only of secondary concern; the quicker the better ofcourse but a (slight) loss in performance while reading/iterating the objects is no problem
- Since this is a long-running process (as in: windows service running 24/7/365) that, occasionally, processes a bulk of this data I want the data to be garbage-collected when I'm done with it; string interning works great but will, in the long run, result in a huge string pool with lots of unused data
- I would like any solutions to be "simple"; adding 15 classes with P/Invokes and inline assembly (exaggerated) is not worth the effort. Code maintainability is high on my list.
This is more of a 'theoretical' question; it's purely out of curiosity / interest that I'm asking. There is no "real" problem, but I can see that in similar situations this might be a problem to someone.
For example: I could do something like this:
public class StringInterningObject
{
private HashSet<string> _items;
public StringInterningObject()
{
_items = new HashSet<string>();
}
public string Add(string value)
{
if (_items.Add(value))
return value; //New item added; return value since it wasn't in the HashSet
//MEH... this will quickly go O(n)
return _items.First(i => i.Equals(value)); //Find (and return) actual item from the HashSet and return it
}
}
But with a large set of (to be de-duplicated) strings this will quickly bog down. I could have a peek at the reference source for HashSet or Dictionary or... and build a similar class that doesn't return bool for the Add() method but the actual string found in the internals/bucket.
The best I could come up with until now is something like:
public class StringInterningObject
{
private ConcurrentDictionary<string, string> _items;
public StringInterningObject()
{
_items = new ConcurrentDictionary<string, string>();
}
public string Add(string value)
{
return _items.AddOrUpdate(value, value, (v, i) => i);
}
}
Which has the "penalty" of having a Key and a Value where I'm actually only interested in the Key. Just a few bytes though, small price to pay. Coincidally this also yields 42% less memory usage; the same result as when using string.Intern() yields.
tolanj came up with System.Xml.NameTable:
public class StringInterningObject
{
private System.Xml.NameTable nt = new System.Xml.NameTable();
public string Add(string value)
{
return nt.Add(value);
}
}
(I removed the lock and string.Empty check (the latter since the NameTable already does that))
xanatos came up with a CachingEqualityComparer:
public class StringInterningObject
{
private class CachingEqualityComparer<T> : IEqualityComparer<T> where T : class
{
public System.WeakReference X { get; private set; }
public System.WeakReference Y { get; private set; }
private readonly IEqualityComparer<T> Comparer;
public CachingEqualityComparer()
{
Comparer = EqualityComparer<T>.Default;
}
public CachingEqualityComparer(IEqualityComparer<T> comparer)
{
Comparer = comparer;
}
public bool Equals(T x, T y)
{
bool result = Comparer.Equals(x, y);
if (result)
{
X = new System.WeakReference(x);
Y = new System.WeakReference(y);
}
return result;
}
public int GetHashCode(T obj)
{
return Comparer.GetHashCode(obj);
}
public T Other(T one)
{
if (object.ReferenceEquals(one, null))
{
return null;
}
object x = X.Target;
object y = Y.Target;
if (x != null && y != null)
{
if (object.ReferenceEquals(one, x))
{
return (T)y;
}
else if (object.ReferenceEquals(one, y))
{
return (T)x;
}
}
return one;
}
}
private CachingEqualityComparer<string> _cmp;
private HashSet<string> _hs;
public StringInterningObject()
{
_cmp = new CachingEqualityComparer<string>();
_hs = new HashSet<string>(_cmp);
}
public string Add(string item)
{
if (!_hs.Add(item))
item = _cmp.Other(item);
return item;
}
}
(Modified slightly to "fit" my "Add() interface")
As per Henk Holterman's request:
public class StringInterningObject
{
private Dictionary<string, string> _items;
public StringInterningObject()
{
_items = new Dictionary<string, string>();
}
public string Add(string value)
{
string result;
if (!_items.TryGetValue(value, out result))
{
_items.Add(value, value);
return value;
}
return result;
}
}
I'm just wondering if there's maybe a neater/better/cooler way to 'solve' my (not so much of an actual) problem. By now I have enough options I guess 
Here are some numbers I came up with for some simple, short, preliminary tests:
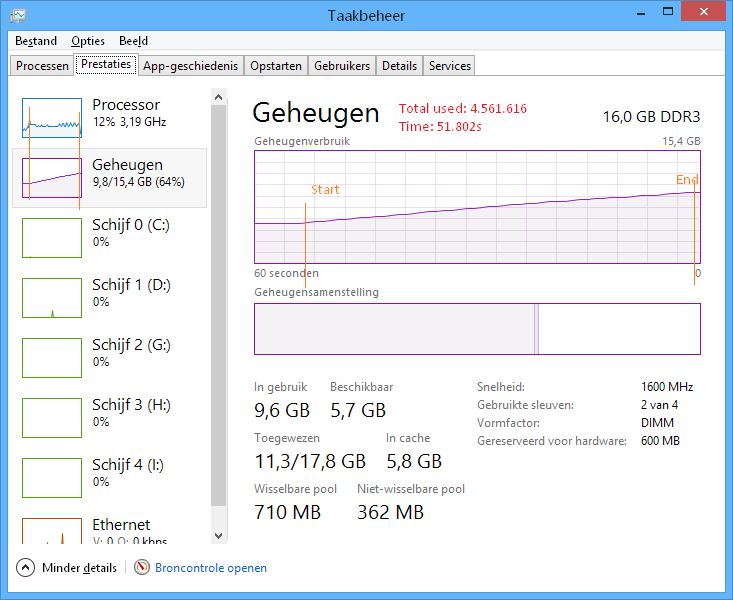
Non optimized
Memory: ~4,5Gb
Load time: ~52s
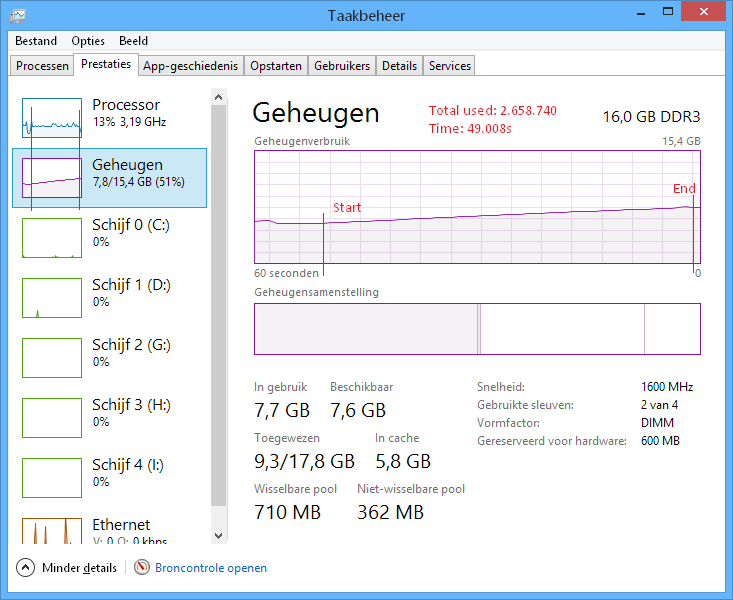
StringInterningObject (see above, the ConcurrentDictionary variant)
Memory: ~2,6Gb
Load time: ~49s
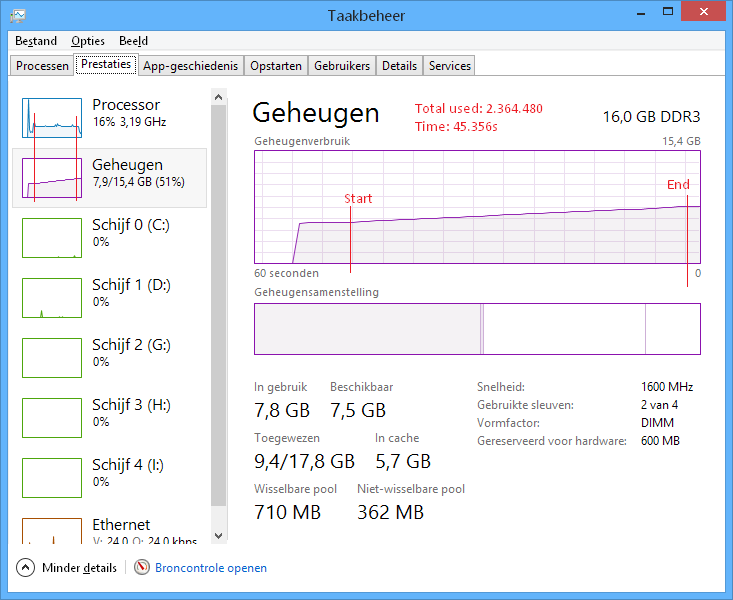
string.Intern()
Memory: ~2,3Gb
Load time: ~45s
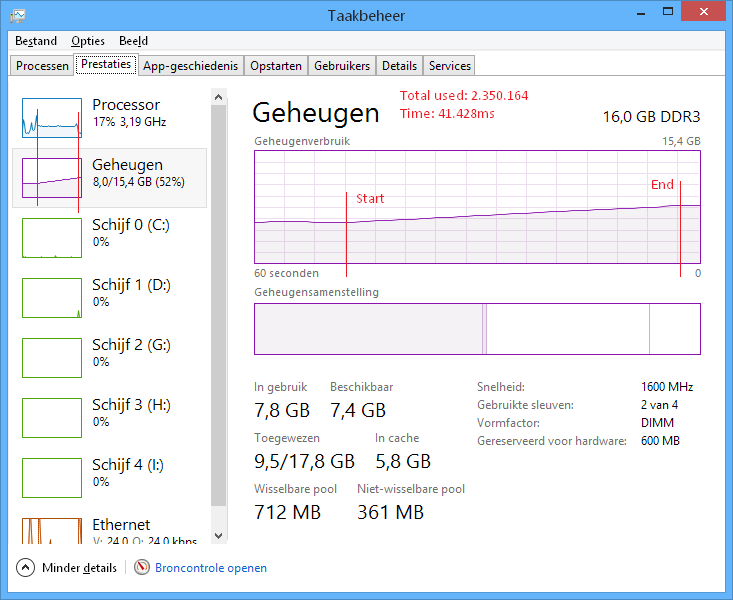
System.Xml.NameTable
Memory: ~2,3Gb
Load time: ~41s
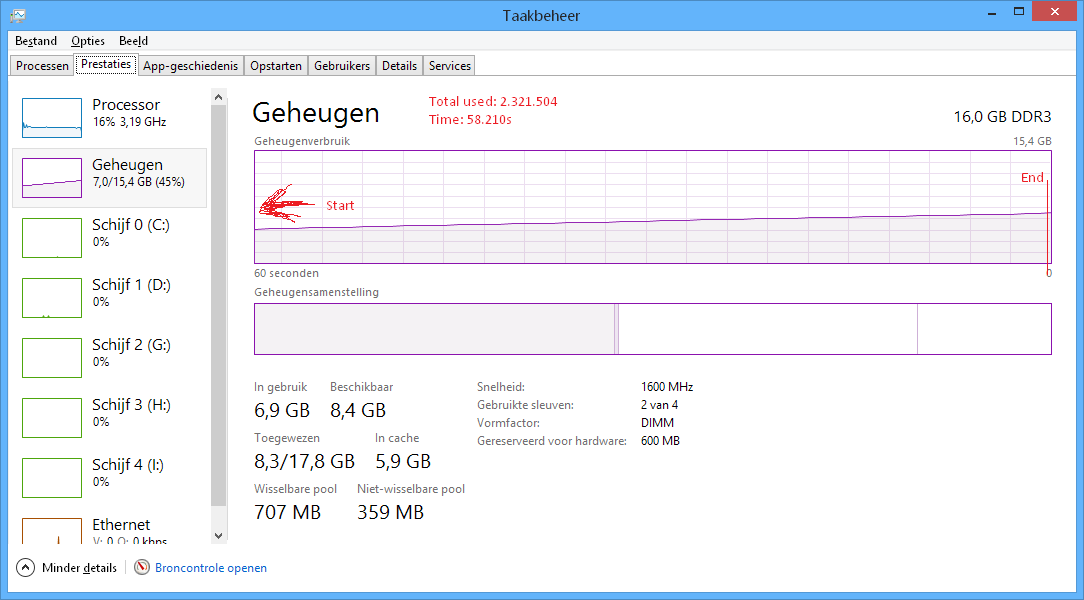
CachingEqualityComparer
Memory: ~2,3Gb
Load time: ~58s
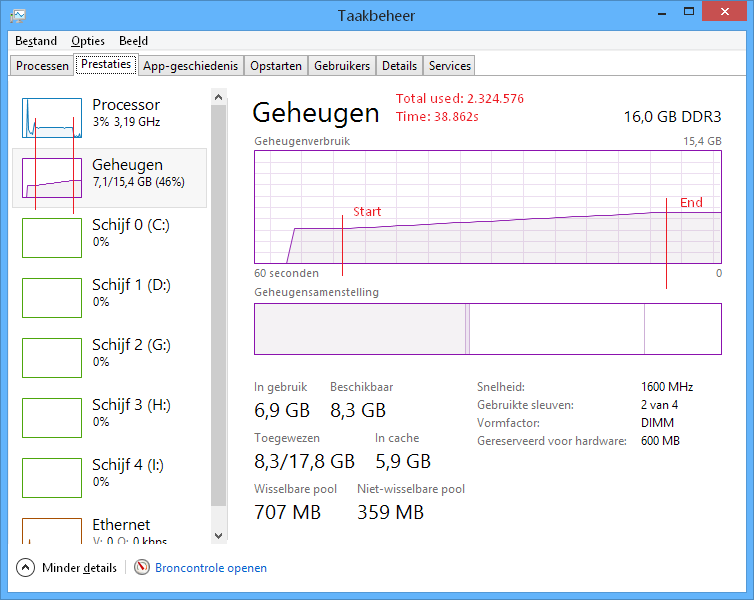
StringInterningObject (see above, the (non-concurrent) Dictionary variant) as per Henk Holterman's request:
Memory: ~2,3Gb
Load time: ~39s
Although the numbers aren't very definitive, it seems that the many memory-allocations for the non-optimized version actually slow down more than using either string.Intern() or the above StringInterningObjects which results in (slightly) longer load times. Also, << See updates. string.Intern() seems to 'win' from StringInterningObject but not by a large margin;
HashSetthat would help in this regard that I missed or something. Or maybe, I dunno, just shouting out wild thoughts here, some compiler directive that would help. – FlyMyObject(millions) I have a lot of duplicate data in memory. If allMyObjects for Amsterdam could reference the same string (which they will when I usestring.Intern()) it is a lot memory friendlier. I guess I am asking for astring.Intern()that would allow garbage collection. – Flystring.Internor not, weak-referenced or not, concurrent at the expense of per-operation cost versus faster at the expense of not being thread-safe). I really must get back to it and release it. In the meantime, writing your own hashset that returns the interned item isn't tricky and I'd go with that. – ClassieclassificationDictionary<string.string>. The other solutions aren't thread-safe either. – Graminivorous