Introduction
R code is written by using Sparklyr package to create database schema. [Reproducible code and database is given]
Existing Result
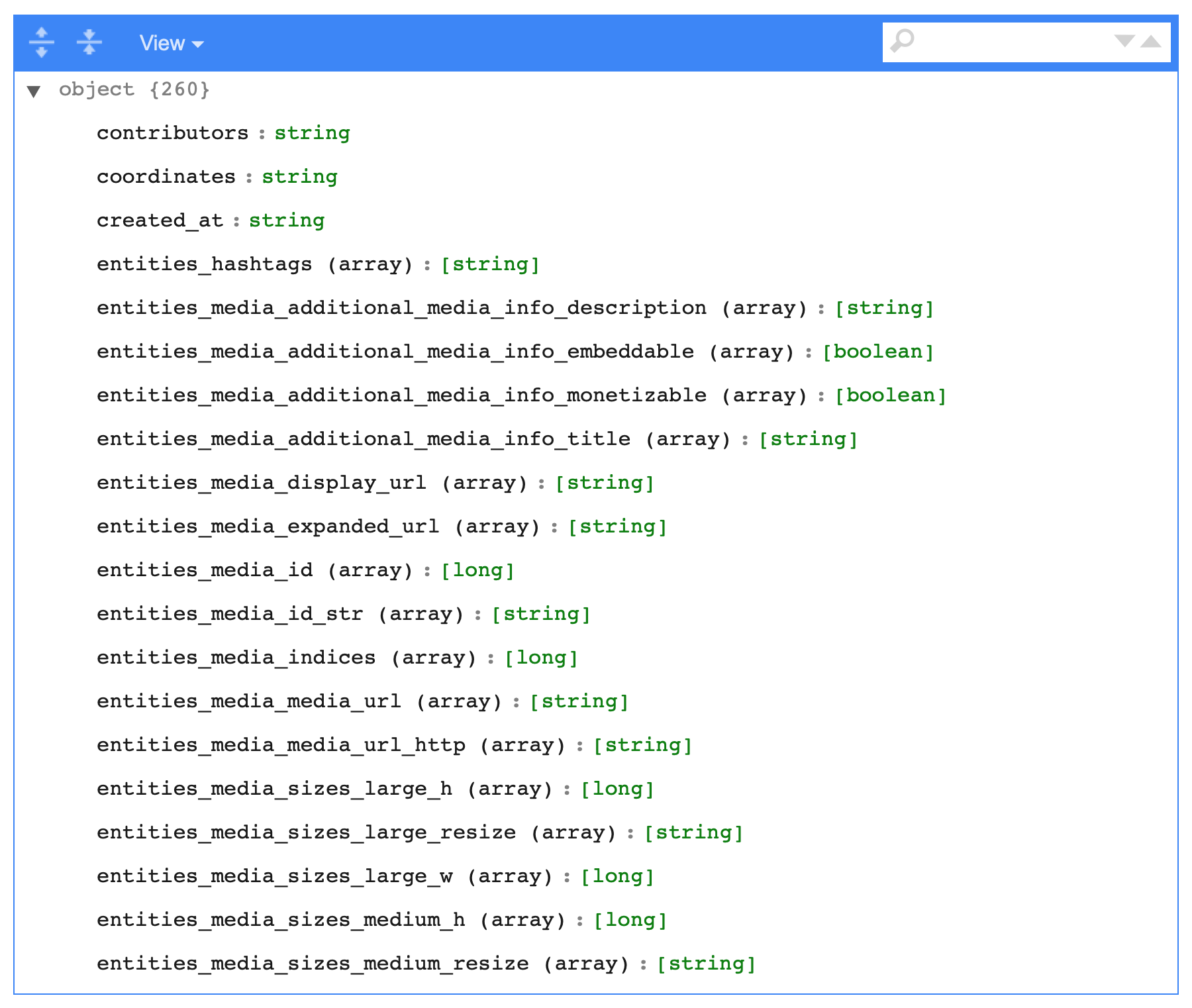
root
|-- contributors : string
|-- created_at : string
|-- entities (struct)
| |-- hashtags (array) : [string]
| |-- media (array)
| | |-- additional_media_info (struct)
| | | |-- description : string
| | | |-- embeddable : boolean
| | | |-- monetizable : bollean
| | |-- diplay_url : string
| | |-- id : long
| | |-- id_str : string
| |-- urls (array)
|-- extended_entities (struct)
|-- retweeted_status (struct)
|-- user (struct)
I want to flatten this structure as below,
Expected Result
root
|-- contributors : string
|-- created_at : string
|-- entities (struct)
|-- entities.hashtags (array) : [string]
|-- entities.media (array)
|-- entities.media.additional_media_info (struct)
|-- entities.media.additional_media_info.description : string
|-- entities.media.additional_media_info.embeddable : boolean
|-- entities.media.additional_media_info.monetizable : bollean
|-- entities.media.diplay_url : string
|-- entities.media.id : long
|-- entities.media.id_str : string
|-- entities.urls (array)
|-- extended_entities (struct)
|-- retweeted_status (struct)
|-- user (struct)
Database Navigate to: Data-178 KB . Then copy the numbered items to a text file named "example". Save to a directory named "../example.json/" created in your working directory.
The R code is written to reproduce the example as below,
Exiting Code
library(sparklyr)
library(dplyr)
library(devtools)
devtools::install_github("mitre/sparklyr.nested")
# If Spark is not installed, then also need:
# spark_install(version = "2.2.0")
library(sparklyr.nested)
library(testthat)
library(jsonlite)
Sys.setenv(SPARK_HOME="/usr/lib/spark")
conf <- spark_config()
conf$'sparklyr.shell.executor-memory' <- "20g"
conf$'sparklyr.shell.driver-memory' <- "20g"
conf$spark.executor.cores <- 16
conf$spark.executor.memory <- "20G"
conf$spark.yarn.am.cores <- 16
conf$spark.yarn.am.memory <- "20G"
conf$spark.executor.instances <- 8
conf$spark.dynamicAllocation.enabled <- "false"
conf$maximizeResourceAllocation <- "true"
conf$spark.default.parallelism <- 32
sc <- spark_connect(master = "local", config = conf, version = '2.2.0') # Connection
sample_tbl <- spark_read_json(sc,name="example",path="example.json", header = TRUE, memory = FALSE, overwrite = TRUE)
sdf_schema_viewer(sample_tbl) # to create db schema
Efforts Taken
Used jsonlite. But it is unable to read big file and within chunks also. It took non ending time. So, I turned towards Sparklyr as it does wonder and read 1 billion records within few seconds. I have done further study for flattening the records upto deep nesting level (because flattening is done in jsonlite package by using flatten() function). But, in Sparklyr, there is no such feature available. Only 1st level flattening could possible in Sparklyr.
I want to flatten the data of different data types and want the output in CSV file.
Apache Drillfor reading 1 Billion data and the conversion in CSV file. Because suggested answer does not help to collect the data in R. At the end, while collecting it shows error and also does not help to convert into CSV file. – Felipa