I wanted to know the same thing, so I measured it.
On my box (AMD FX(tm)-8150 Eight-Core Processor at 3.612361 GHz),
locking and unlocking an unlocked mutex that is in its own cache line and is already cached, takes 47 clocks (13 ns).
Due to synchronization between two cores (I used CPU #0 and #1),
I could only call a lock/unlock pair once every 102 ns on two threads,
so once every 51 ns, from which one can conclude that it takes roughly 38 ns to recover after a thread does an unlock before the next thread can lock it again.
The program that I used to investigate this can be found here:
https://github.com/CarloWood/ai-statefultask-testsuite/blob/b69b112e2e91d35b56a39f41809d3e3de2f9e4b8/src/mutex_test.cxx
Note that it has a few hardcoded values specific for my box (xrange, yrange and rdtsc overhead), so you probably have to experiment with it before it will work for you.
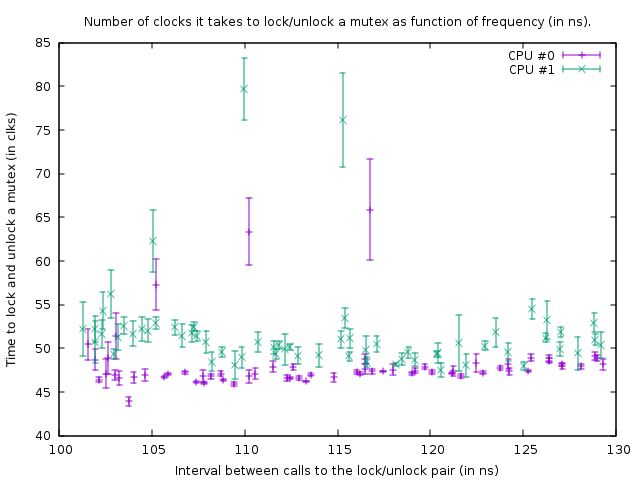
The graph it produces in that state is:
![enter image description here]()
This shows the result of benchmark runs on the following code:
uint64_t do_Ndec(int thread, int loop_count)
{
uint64_t start;
uint64_t end;
int __d0;
asm volatile ("rdtsc\n\tshl $32, %%rdx\n\tor %%rdx, %0" : "=a" (start) : : "%rdx");
mutex.lock();
mutex.unlock();
asm volatile ("rdtsc\n\tshl $32, %%rdx\n\tor %%rdx, %0" : "=a" (end) : : "%rdx");
asm volatile ("\n1:\n\tdecl %%ecx\n\tjnz 1b" : "=c" (__d0) : "c" (loop_count - thread) : "cc");
return end - start;
}
The two rdtsc calls measure the number of clocks that it takes to lock and unlock `mutex' (with an overhead of 39 clocks for the rdtsc calls on my box). The third asm is a delay loop. The size of the delay loop is 1 count smaller for thread 1 than it is for thread 0, so thread 1 is slightly faster.
The above function is called in a tight loop of size 100,000. Despite that the function is slightly faster for thread 1, both loops synchronize because of the call to the mutex. This is visible in the graph from the fact that the number of clocks measured for the lock/unlock pair is slightly larger for thread 1, to account for the shorter delay in the loop below it.
In the above graph the bottom right point is a measurement with a delay loop_count of 150, and then following the points at the bottom, towards the left, the loop_count is reduced by one each measurement. When it becomes 77 the function is called every 102 ns in both threads. If subsequently loop_count is reduced even further it is no longer possible to synchronize the threads and the mutex starts to be actually locked most of the time, resulting in an increased amount of clocks that it takes to do the lock/unlock. Also the average time of the function call increases because of this; so the plot points now go up and towards the right again.
From this we can conclude that locking and unlocking a mutex every 50 ns is not a problem on my box.
All in all my conclusion is that the answer to question of OP is that adding more mutexes is better as long as that results in less contention.
Try to lock mutexes as short as possible. The only reason to put them -say- outside a loop would be if that loop loops faster than once every 100 ns (or rather, number of threads that want to run that loop at the same time times 50 ns) or when 13 ns times the loop size is more delay than the delay you get by contention.
EDIT: I got a lot more knowledgable on the subject now and start to doubt the conclusion that I presented here. First of all, CPU 0 and 1 turn out to be hyper-threaded; even though AMD claims to have 8 real cores, there is certainly something very fishy because the delays between two other cores is much larger (ie, 0 and 1 form a pair, as do 2 and 3, 4 and 5, and 6 and 7). Secondly, the std::mutex is implemented in way that it spin locks for a bit before actually doing system calls when it fails to immediately obtain the lock on a mutex (which no doubt will be extremely slow). So what I have measured here is the absolute most ideal situtation and in practise locking and unlocking might take drastically more time per lock/unlock.
Bottom line, a mutex is implemented with atomics. To synchronize atomics between cores an internal bus must be locked which freezes the corresponding cache line for several hundred clock cycles. In the case that a lock can not be obtained, a system call has to be performed to put the thread to sleep; that is obviously extremely slow (system calls are in the order of 10 mircoseconds). Normally that is not really a problem because that thread has to sleep anyway-- but it could be a problem with high contention where a thread can't obtain the lock for the time that it normally spins and so does the system call, but CAN take the lock shortly there after. For example, if several threads lock and unlock a mutex in a tight loop and each keeps the lock for 1 microsecond or so, then they might be slowed down enormously by the fact that they are constantly put to sleep and woken up again. Also, once a thread sleeps and another thread has to wake it up, that thread has to do a system call and is delayed ~10 microseconds; this delay thus happens while unlocking a mutex when another thread is waiting for that mutex in the kernel (after spinning took too long).