I cannot see the difference between what I am doing and the working Google TFP example, whose structure I am following. What am I doing wrong/should I be doing differently?
[Setup: Win 10 Home 64-bit 20H2, Python 3.7, TF2.4.1, TFP 0.12.2, running in Jupyter Lab]
I have been building a model step by step following the example of TFP Probabilistic Layers Regression. The Case 1 code runs fine, but my parallel model doesn't and I cannot see the difference that might cause this
yhat = model(x_tst)
to fail with message Input 0 of layer sequential_14 is incompatible with the layer: : expected min_ndim=2, found ndim=1. Full shape received: (2019,) (which is the correct 1D size of x_tst)
For comparison: Google's load_dataset function for the TFP example returns y, x, x_tst, which are all np.ndarray of size 150, whereas I read data from a csv file with pandas.read_csv, split it into train_ and test_datasets and then take 1 col of data as independent variable 'g' and dependent variable 'redz' from the training dataset.
I know x, y, etc. need to be np.ndarray, but one does not create ndarray directly, so I have...
x = np.array(train_dataset['g'])
y = np.array(train_dataset['redz'])
x_tst = np.array(test_dataset['g'])
where x, y, x_tst are all 1-dimensional - just like the TFP example.
The model itself runs
model = tf.keras.Sequential([
tf.keras.layers.Dense(1),
tfp.layers.DistributionLambda(lambda t: tfd.Normal(loc=t, scale=1)),
])
# Do inference.
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.01), loss=negloglik)
model.fit(x, y, epochs=1, verbose=False);
(and when plotted gives the expected output for the google data - I don't get this far):
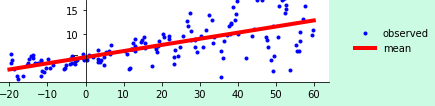
But, per the example when I try to "profit" by doing yhat = model(x_tst) I get the dimensions error given above.
What's wrong?
(If I try mode.predict I think I hit a known bug/gap in TFP; then it fails the assert)
Update - Explicit Reshape Resolves Issue
The hint from Frightera led to further investigation: x_tst had shape (2019,)
Reshaping by x_tst = x_tst.rehape(2019,1) resolved the issue. Is TF inconsistent in its requirements or is there some good reason that the explicit final dimension 1 was required? Who knows. At least predictions can be made now.