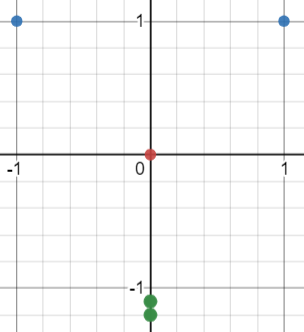
If we have some datapoints:
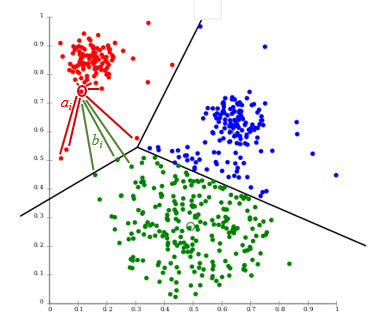
And we use, for example, k-means to segment; are the resulting segments not such that every point is closest to the center-of-mass of its respective cluster? And if so, when silhouette score compares ai (average distance to intra-cluster points) vs bi (average distance to extra-cluster points), how can it ever be the case that the score is negative, or that bi is less than ai?
I can see maybe for different classification algorithms, some more sophisticated ones may cluster differently, or some points are assigned incorrectly. But how does this happen for k-means?