I think the short answer is NO. To have multi-index columns, the dataframe should have two (or more) rows to be converted into headers (like columns for multi-index rows). If you have this kind of dataframe, creating multi-index header is not so difficult. It can be done in a very long line of code, and you can reuse it at any other dataframe, only the row numbers of the headers should be kept in mind & change if differs:
df = pd.DataFrame({'a':['foo_0', 'bar_0', 1, 2, 3], 'b':['foo_0', 'bar_1', 11, 12, 13],
'c':['foo_1', 'bar_0', 21, 22, 23], 'd':['foo_1', 'bar_1', 31, 32, 33]})
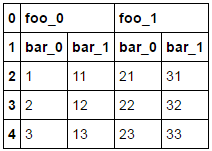
The dataframe:
a b c d
0 foo_0 foo_0 foo_1 foo_1
1 bar_0 bar_1 bar_0 bar_1
2 1 11 21 31
3 2 12 22 32
4 3 13 23 33
Creating multi-index object:
arrays = [df.iloc[0].tolist(), df.iloc[1].tolist()]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df.columns = index
Multi-index header result:
first foo_0 foo_1
second bar_0 bar_1 bar_0 bar_1
0 foo_0 foo_0 foo_1 foo_1
1 bar_0 bar_1 bar_0 bar_1
2 1 11 21 31
3 2 12 22 32
4 3 13 23 33
Finally we need to drop 0-1 rows then reset the row index:
df = df.iloc[2:].reset_index(drop=True)
The "one-line" version (only thing you have to change is to specify header indexes and the dataframe itself):
idx_first_header = 0
idx_second_header = 1
df.columns = pd.MultiIndex.from_tuples(list(zip(*[df.iloc[idx_first_header].tolist(),
df.iloc[idx_second_header].tolist()])), names=['first', 'second'])
df = df.drop([idx_first_header, idx_second_header], axis=0).reset_index(drop=True)