I am doing a computer simulation for some physical system of finite size, and after this I am doing extrapolation to the infinity (Thermodynamic limit). Some theory says that data should scale linearly with system size, so I am doing linear regression.
The data I have is noisy, but for each data point I can estimate errorbars. So, for example data points looks like:
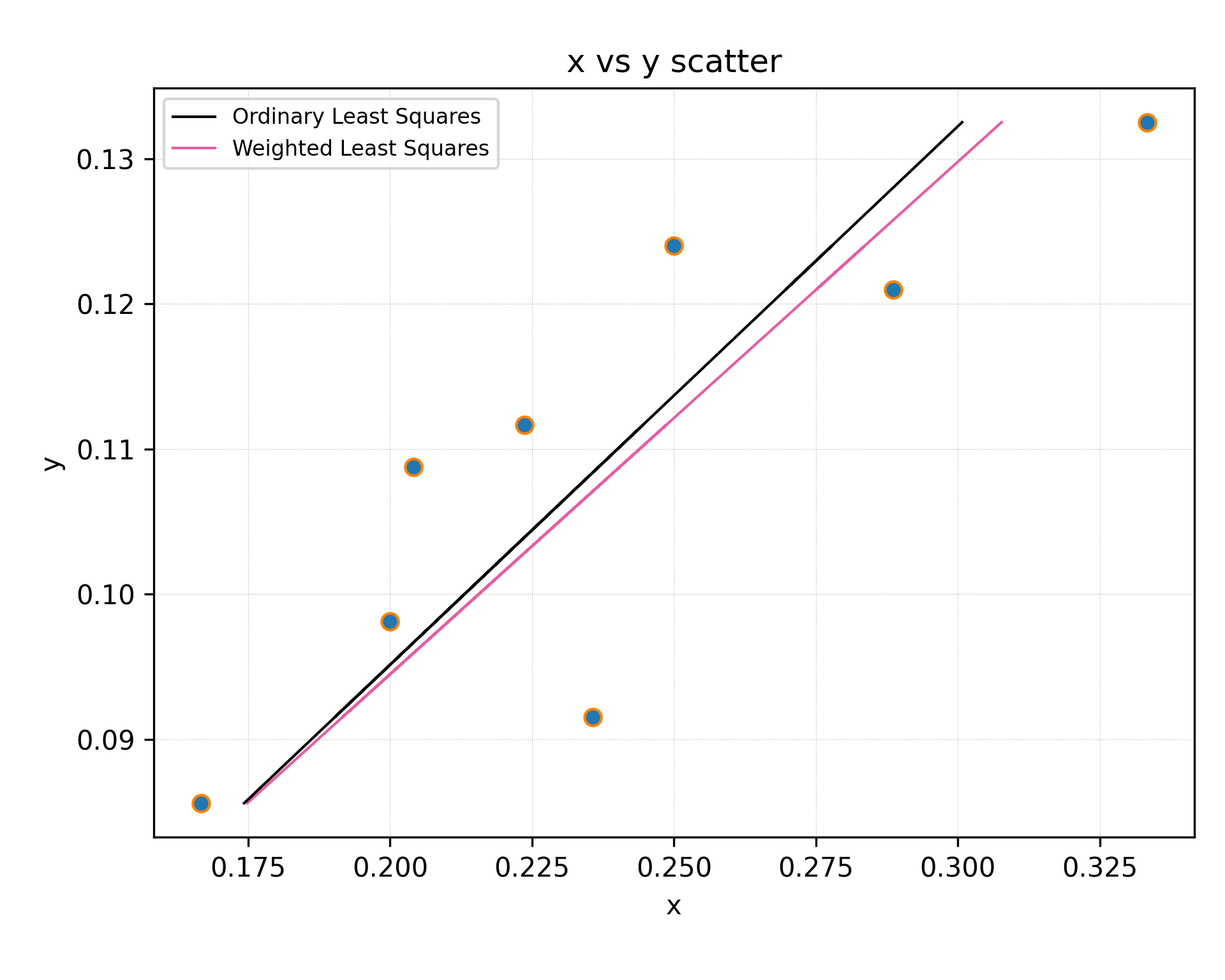
x_list = [0.3333333333333333, 0.2886751345948129, 0.25, 0.23570226039551587, 0.22360679774997896, 0.20412414523193154, 0.2, 0.16666666666666666]
y_list = [0.13250359351851854, 0.12098339583333334, 0.12398501145833334, 0.09152715, 0.11167239583333334, 0.10876248333333333, 0.09814170444444444, 0.08560799305555555]
y_err = [0.003306749165349316, 0.003818446389148108, 0.0056036878203831785, 0.0036635292592592595, 0.0037034897788415424, 0.007576672222222223, 0.002981084130692832, 0.0034913019065973983]
Let's say I am trying to do this in Python.
First way that I know is:
m, c, r_value, p_value, std_err = scipy.stats.linregress(x_list, y_list)I understand this gives me errorbars of the result, but this does not take into account errorbars of the initial data.
Second way that I know is:
m, c = numpy.polynomial.polynomial.polyfit(x_list, y_list, 1, w = [1.0 / ty for ty in y_err], full=False)
Here we use the inverse of the errorbar for the each point as a weight that is used in the least square approximation. So if a point is not really that reliable it will not influence result a lot, which is reasonable.
But I can not figure out how to get something that combines both these methods.
What I really want is what second method does, meaning use regression when every point influences the result with different weight. But at the same time I want to know how accurate my result is, meaning, I want to know what are errorbars of the resulting coefficients.
How can I do this?
y_errseries as weight matrix? – Homoio