In the paper describing BERT, there is this paragraph about WordPiece Embeddings.
We use WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary. The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B. As shown in Figure 1, we denote input embedding as E, the final hidden vector of the special [CLS] token as C 2 RH, and the final hidden vector for the ith input token as Ti 2 RH. For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings. A visualization of this construction can be seen in Figure 2.
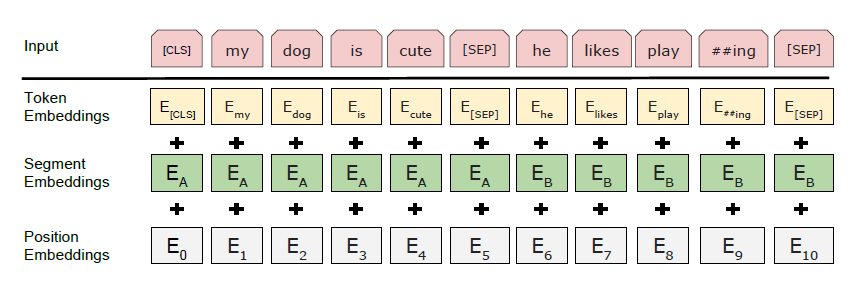
As I understand, WordPiece splits Words into wordpieces like #I #like #swim #ing, but it does not generate Embeddings. But I did not find anything in the paper and on other sources how those Token Embeddings are generated. Are they pretrained before the actual Pre-training? How? Or are they randomly initialized?