This is my first attempt at doing something with CNNs, so I am probably doing something very stupid - but can't figure out where I am wrong...
The model seems to be learning fine, but the validation accuracy is not improving (ever - even after the first epoch), and validation loss is actually increasing with time. It doesn't look like I am overfiting (after 1 epoch?) - must we off in some other way.
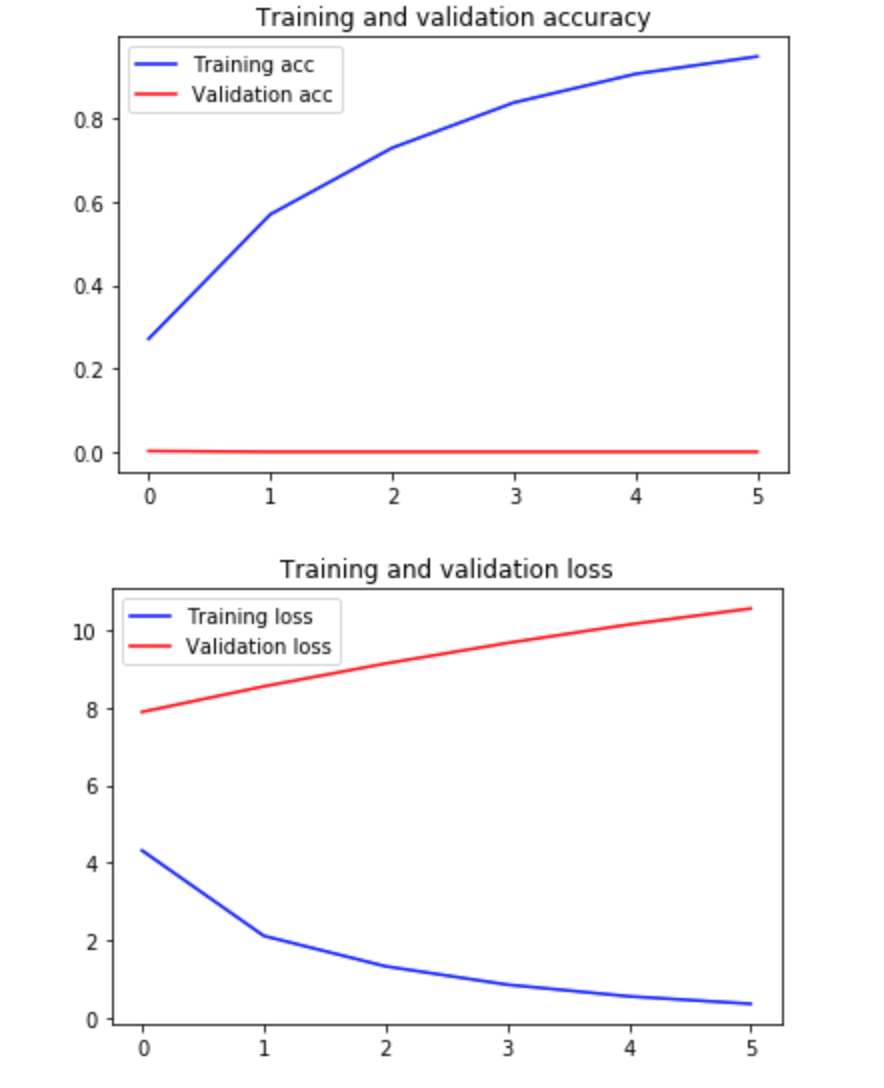{kind=link}
I am training a CNN network - I have ~100k images of various plants (1000 classes) and want to fine-tune ResNet50 to create a muticlass classifier. Images are of various sizes, I load them like so:
from keras.preprocessing import image
def path_to_tensor(img_path):
# loads RGB image as PIL.Image.Image type
img = image.load_img(img_path, target_size=(IMG_HEIGHT, IMG_HEIGHT))
# convert PIL.Image.Image type to 3D tensor with shape (IMG_HEIGHT, IMG_HEIGHT, 3)
x = image.img_to_array(img)
# convert 3D tensor to 4D tensor with shape (1, IMG_HEIGHT, IMG_HEIGHT, 3) and return 4D tensor
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
list_of_tensors = [path_to_tensor(img_path) for img_path in img_paths] #can use tqdm(img_paths) for data
return np.vstack(list_of_tensors)enter code here
The database is large (does not fit into memory) and had to create my own generator to provide both reading from the disk and augmentation. (I know Keras has .flow_from_directory() - but my data is not structured this way - it is just a dump of 100k images mixed with 100k metadata files). I probably should have created a script to structure them better and not create my own generators, but the problem is likely somewhere else.
The generator version below doesn't do any augmentation for the time being - just rescaling:
def generate_batches_from_train_folder(images_to_read, labels, batchsize = BATCH_SIZE):
#Generator that returns batches of images ('xs') and labels ('ys') from the train folder
#:param string filepath: Full filepath of files to read - this needs to be a list of image files
#:param np.array: list of all labels for the images_to_read - those need to be one-hot-encoded
#:param int batchsize: Size of the batches that should be generated.
#:return: (ndarray, ndarray) (xs, ys): Yields a tuple which contains a full batch of images and labels.
dimensions = (BATCH_SIZE, IMG_HEIGHT, IMG_HEIGHT, 3)
train_datagen = ImageDataGenerator(
rescale=1./255,
#rotation_range=20,
#zoom_range=0.2,
#fill_mode='nearest',
#horizontal_flip=True
)
# needs to be on a infinite loop for the generator to work
while 1:
filesize = len(images_to_read)
# count how many entries we have read
n_entries = 0
# as long as we haven't read all entries from the file: keep reading
while n_entries < (filesize - batchsize):
# start the next batch at index 0
# create numpy arrays of input data (features)
# - this is already shaped as a tensor (output of the support function paths_to_tensor)
xs = paths_to_tensor(images_to_read[n_entries : n_entries + batchsize])
# and label info. Contains 1000 labels in my case for each possible plant species
ys = labels[n_entries : n_entries + batchsize]
# we have read one more batch from this file
n_entries += batchsize
#perform online augmentation on the xs and ys
augmented_generator = train_datagen.flow(xs, ys, batch_size = batchsize)
yield next(augmented_generator)
This is how I define my model:
def get_model():
# define the model
base_net = ResNet50(input_shape=DIMENSIONS, weights='imagenet', include_top=False)
# Freeze the layers which you don't want to train. Here I am freezing all of them
for layer in base_net.layers:
layer.trainable = False
x = base_net.output
#for resnet50
x = Flatten()(x)
x = Dense(512, activation="relu")(x)
x = Dropout(0.5)(x)
x = Dense(1000, activation='softmax', name='predictions')(x)
model = Model(inputs=base_net.input, outputs=x)
# compile the model
model.compile(
loss='categorical_crossentropy',
optimizer=optimizers.Adam(1e-3),
metrics=['acc'])
return model
So, as a result I have 1,562,088 trainable parameters for roughly 70k images
I then use a 5-fold cross validation, but the model doesn't work on any of the folds, so I will not be including the full code here, the relevant bit is this:
trial_fold = temp_model.fit_generator(
train_generator,
steps_per_epoch = len(X_train_path) // BATCH_SIZE,
epochs = 50,
verbose = 1,
validation_data = (xs_v,ys_v),#valid_generator,
#validation_steps= len(X_valid_path) // BATCH_SIZE,
callbacks = callbacks,
shuffle=True)
I have done various things - made sure my generator is actually working, tried to play with the last few layers of the network by reducing the size of the fully connected layer, tried augmentation - nothing helps...
I don't think the number of parameters in the network is too large - I know other people have done pretty much the same thing and got accuracy closer to 0.5, but my models seem to be overfitting like crazy. Any ideas on how to tackle this will be much appreciated!
Update 1:
I have decided to stop reinventing stuff and sorted by files to work with .flow_from_directory() procedure. To make sure I am importing the right format (triggered by the Ioannis Nasios comment below) - I made sure to the preprocessing_unit() from keras's resnet50 application.
I also decided to check out if the model is actually producing something useful - I computed botleneck features for my dataset and then used a random forest to predict the classes. It did work and I got accuracy of around 0.4
So, I guess I definitely had a problem with an input format of my images. As a next step, I will fine-tune the model (with a new top layer) to see if the problem remains...
Update 2:
I think the problem was with image preprocessing. I ended up not fine tuning in the end and just extracted botleneck layer and training linear_SVC() - got accuracy of around 60% of train and around 45% of test datasets.