I've been working on document level sentiment analysis since past 1 year. Document level sentiment analysis provides the sentiment of the complete document. For example - The text "Nokia is good but vodafone sucks big time" would have a negative polarity associated with it as it would be agnostic to the entities Nokia and Vodafone. How would it be possible to get entity level sentiment, like positive for Nokia but negative for Vodafone ? Are there any research papers providing a solution to such problems ?
Sentiment Analysis of Entity (Entity-level Sentiment Analysis)
Asked Answered
You might want to look for papers about reputation management. Doing that fully automatically is an open research question, though. –
Haircloth
You can try Aspect-level or Entity-level Sentiment Analysis. There are good efforts have been already done to find the opinions about the aspects in a sentence. You can find some of works here. You can also go further and deeper and review those papers that are related to feature (aspect) extraction. What does it mean? Let me give you an example:
"The quality of screen is great, however, the battery life is short."
Document-level sentiment analysis may not give us the real sense of this document here because we have one positive and one negative sentence in the document. However, by aspect-based (aspect-level) opinion mining, we can figure out the senses/polarities towards different entities in the document separately. By doing feature extraction, in the first step, you try to find the features (aspects) in different sentences (in here "quality of screen" or simply "quality" and "battery life"). Afterwards, when you have these aspects, you try to extract opinions related to these aspects ("great" for "quality" and "short" for "battery life"). In researches and academic papers, we also name features (aspects) as target words (those words or entities on which users comment), and the opinions as opinion words, the comments that have been stated about the target words.
By searching the keywords that I have just mentioned, you can become more familiar with these concepts.
Aspect-level is a special case of entity level sentiment analysis. I think we need something broader for entity level sentiment analysis. Most of ABSA challenge related works additionally are in a very limited domain range. –
Mitziemitzl
@MonaJalal You are right, however, people sometimes use these two terms, aspect- and entity-level sentiment analysis (SA), interchangeably in the literature. Generally speaking, in aspect-level SA, "the goal is to find and aggregate sentiment on entities mentioned within documents or aspects of them." Schouten and Frasincar (2016) –
Themselves
You could look for entities and their coreferents, and have a simple heuristic like giving each entity sentiment from the closest sentiment term, perhaps closest by distance in a dependency parse tree, as opposed to linearly. Each of those steps seems to be an open research topic.
http://scholar.google.com/scholar?q=entity+identification
http://scholar.google.com/scholar?q=coreference+resolution
and what about other languages ? or slang and unstructured English where dependency parse trees are most prob. not accurate ? is there some statistical rules or any other approaches ? –
Peril
@HadyElsahar All of these problems that you mentioned are major challenges in this field of study. Characteristics of different languages can directly effect on the process of analyzing documents. For example, Persian language differs from English in many aspects. As a result, you may not be able to deal with challenges in Persian the same way as English (For instance, Tokenizing is rather simple in English, but not that easy in Persian due to the existence of some affixes). Moreover, Parse tree is only one option for solving the problem. You can use other methods as your feature as well. –
Themselves
This can be achieved using Google Cloud Natural Language API.
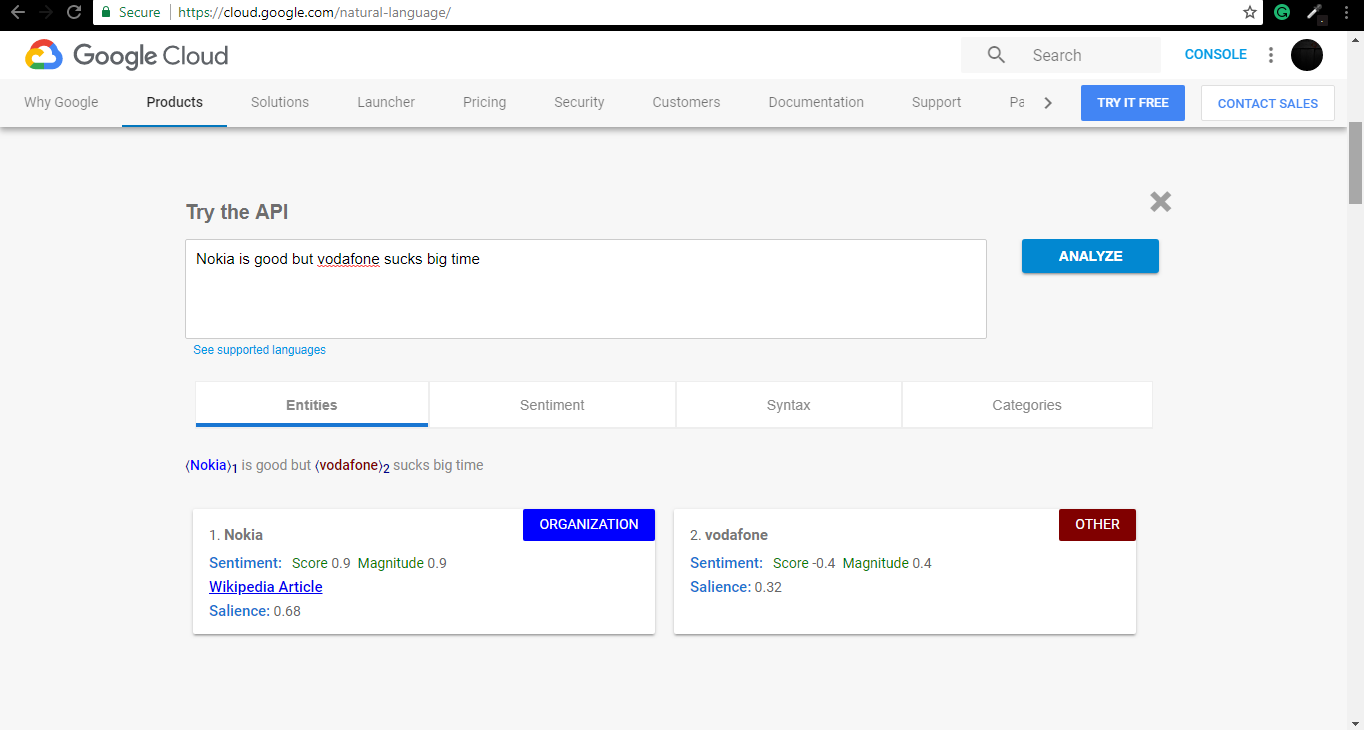
What other tools is available? –
Mitziemitzl
Amazon Comprehend is another NLP tool I came across. –
Wilie
Comprehend doesn't do entity-level sentiment –
Mitziemitzl
I also tried getting research articles on this but haven't found any. I would suggest you to try using the aspect based sentiment analysis algorithms. The similarity i found is there we recognize aspects of a single entity in a sentence and then find the sentiment of each aspect.Similarly we can train our model using the same algorithm which can detect the entities as it does for aspects and find the sentiment of such entities. I didn't try this but I am going to.Let me know if this worked or not.Also there are various ways to do this. The following are the links for few articles.
http://arxiv.org/pdf/1605.08900v1.pdf https://cs224d.stanford.edu/reports/MarxElliot.pdf
May I note that this question is 3 years old? Not saying further answers to this question aren't invited, especially if it can benefit future readers, but I feel advice for the OP him/herself is a little too late at this point to be relevant. –
Inside
© 2022 - 2024 — McMap. All rights reserved.