Tl;dr: "How can I push a message through a bunch of asynchronous, unordered microservices and know when that message has made it through each of them?"
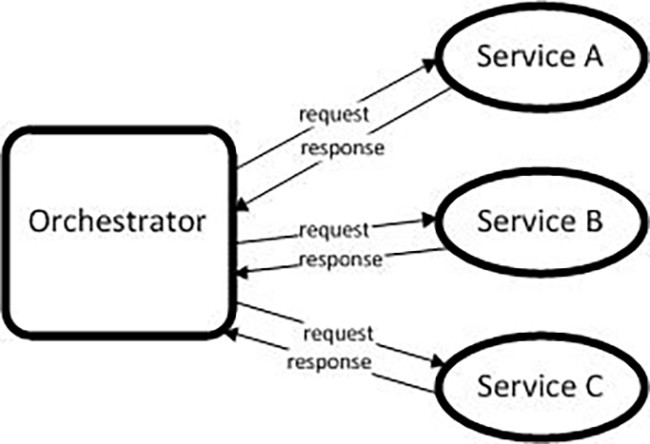
I'm struggling to find the right messaging system/protocol for a specific microservices architecture. This isn't a "which is best" question, but a question about what my options are for a design pattern/protocol.
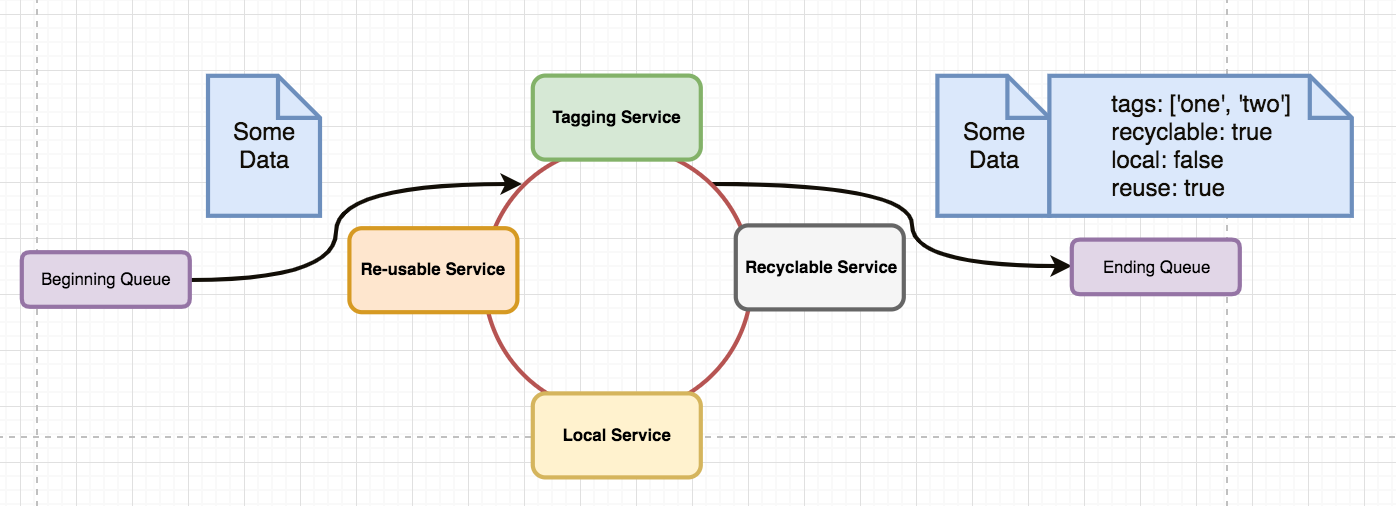
- I have a message on the beginning queue. Let's say a RabbitMQ message with serialized JSON
- I need that message to go through an arbitrary number of microservices
- Each of those microservices are long running, must be independent, and may be implemented in a variety of languages
- The order of services the message goes through does not matter. In fact, it should not be synchronous.
- Each service can append data to the original message, but that data is ignored by the other services. There should be no merge conflicts (each service writes a unique key). No service will change or destroy data.
- Once all the services have had their turn, the message should be published to a second RabbitMQ queue with the original data and the new data.
- The microservices will have no other side-effects. If this were all in one monolithic application (and in the same language), functional programming would be perfect.
So, the question is, what is an appropriate way to manage that message through the various services? I don't want to have to do one at a time, and the order isn't important. But, if that's the case, how can the system know when all the services have had their whack and the final message can be written onto the ending queue (to have the next batch of services have their go).
The only, semi-elegant solution I could come up with was
- to have the first service that encounters a message write that message to common storage (say mongodb)
- Have each service do its thing, mark that it has completed for that message, and then check to see if all the services have had their turn
- If so, that last service would publish the message
But that still requires each service to be aware of all the other services and requires each service to leave its mark. Neither of those is desired.
I am open to a "Shepherd" service of some kind.
I would appreciate any options that I have missed, and am willing to concede that their may be a better, fundamental design.
Thank you.