I've already read several similar StackOverflow posts and none of them were able to resolve my issue.
The Issue
I have a PDF that's being generated by WkHTMLtoPDF which contains a unicode RIGHT SINGLE QUOTATION MARK (U+2019, or ’) character. Rendered in a browser, the output looks like the following:

When I run this through WkHTMLtoPDF, I get the following:

The Code
I'm using the following for my CSS:
@font-face {
font-family: localGeorgia;
src: url("file:///usr/share/fonts/truetype/georgia/GEORGIA.TTF");
}
body {
overflow: visible !important;
font-family: localGeorgia, Georgia, Times, "Times New Roman", serif;
font-size: 12px;
}
I have also copied the Georgia font from my local computer to the server (there are several files in the /usr/share/fonts/truetype/georgia/ directory) and I have run fc-cache -fv to clear the font cache and run fc-list to verify that Georgia was properly installed. The localGeorgia font family was added as a formality because I still wasn't getting a working display.
I've verified both via the online docs and my operating system's character map that the Georgia font does support the RIGHT SINGLE QUOTATION MARK (see below) although I don't know how to prove definitively that this glyph is in the TrueType file (I'm not familiar with opening or parsing TrueType files)
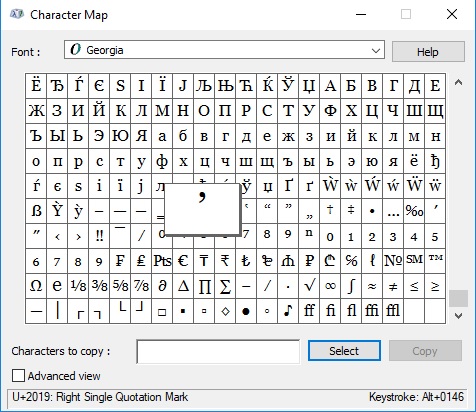
At this point it's unclear to me why WkHTMLtoPDF is displaying this mess of characters instead of the proper unicode glyph
Additional details (environment and such)
I'm running Ubuntu 16.04
Laravel version 5.3
I'm using Laravel-Snappy version 0.3.3 (which is using KNP-Snappy version 0.4.3)
My config for Snappy is pretty straight-forward:
<?php
return array(
'pdf' => array(
'enabled' => true,
'binary' => base_path('vendor/h4cc/wkhtmltopdf-amd64/bin/wkhtmltopdf-amd64'),
'timeout' => false,
'options' => array(),
'env' => array(),
),
'image' => array(
'enabled' => false,
'binary' => '/usr/local/bin/wkhtmltoimage',
'timeout' => false,
'options' => array(),
'env' => array(),
),
);
The installed wkhtmltopdf version is 0.12.3 (with patched qt)
To generate the PDF I'm calling ->render() on the View, passing this to PDF::loadHTML, then calling ->inline() on the result and returning a response. Here's a minimal example of how I'm generating the PDF:
$property = Property::find(1);
$view = View::make("pdf.flier")->with(["property" => $property]);
$pdf = PDF::loadHTML($view->render())->inline();
return response($pdf)->header("application/pdf")->header("Content-Disposition", "attachment; filename=flier.pdf");
The HTML is incredibly simple:
<html>
<head>
<base href="{{ url("/") }}" />
<link rel="stylesheet" type="text/css" href="css/flier.css" />
</head>
<body>
<img src="{{ $property->image }}" />
<h1>{{ $property->title }}</h1>
</body>
</html>
The CSS gives the h1 an absolute position over top of the image
<meta http-equiv="Content-type" content="text/html; charset=utf-8" /><meta charset="UTF-8" />fixed the issue for me – Paleozoology