I have a column in a csv that looks like this:
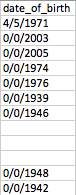
I am using this code to test how the splitting of the dates is working:
LOAD CSV WITH HEADERS FROM
'file:///..some_csv.csv' AS line
WITH
SPLIT(line.date_of_birth, '/') AS date_of_birth
return date_of_birth;
This code block works fine and gives me what I'd expect, which is a collection of three values for each date, or perhaps a null if there was no date ( e.g,
[4, 5, 1971]
[0, 0, 2003]
[0, 0, 2005]
. . .
null
null
. . .
My question is, what is this problem with the nulls that are created, and why can't I do a MERGE when there are nulls?
LOAD CSV WITH HEADERS FROM
'file:///..some_csv.csv' AS line
WITH
SPLIT(line.date_of_birth, '/') AS date_of_birth, line
MERGE (p:Person {
date_of_birth: date_of_birth
});
This block above gives me the error:
Cannot merge node using null property value for date_of_birth
I have searched around and have only found one other SO question about this error, which has no answer. Other searches didn't help.
I was under the impression that if there isn't a value, then Neo4j simply doesn't create the element.
I figured maybe the node can't be generated since, after all, how can a node be generated if there is no value to generate it from? So, since I know there are no ID's missing, maybe I could MERGE with ID and date, so Neo4j always sees a value.
But this code didn't fare any better (same error message):
LOAD CSV WITH HEADERS FROM
'file:///..some_csv.csv' AS line
WITH
SPLIT(line.date_of_birth, '/') AS date_of_birth, line
MERGE (p:Person {
ID: line.ID
,date_of_birth: date_of_birth
});
My next idea is that maybe this error is because I'm trying to split a null value on slashes? Maybe the whole issue is due to the SPLIT.
But alas, same error when simplified to this:
LOAD CSV WITH HEADERS FROM
'file:///..some_csv.csv' AS line
WITH line
MERGE (p:Person {
subject_person_id: line.subject_person_id
,date_of_birth: line.date_of_birth
});
So I don't really understand the cause of the error. Thanks for looking at this.
EDIT
Both @stdob-- and @cybersam have both answered with equally excellent responses, if you came here via Google please consider them as if both were accepted