I fitted a proportional odds cumulative logit model on ordinal data using MASS's polr function using (in this case on data giving the preference for different kinds of cheese) :
data=read.csv("https://www.dropbox.com/s/psj74dx8ohnrdlp/cheese.csv?dl=1")
data$response=factor(data$response, ordered=T) # make response into ordered factor
head(data)
cheese response count
1 A 1 0
2 A 2 0
3 A 3 1
4 A 4 7
5 A 5 8
6 A 6 8
library(MASS)
fit=polr(response ~ cheese, weights=count, data=data, Hess=TRUE, method="logistic")
To plot the predictions of the model I made an effect plot using
library(effects)
library(colorRamps)
plot(allEffects(fit),ylab="Response",type="probability",style="stacked",colors=colorRampPalette(c("white","red"))(9))
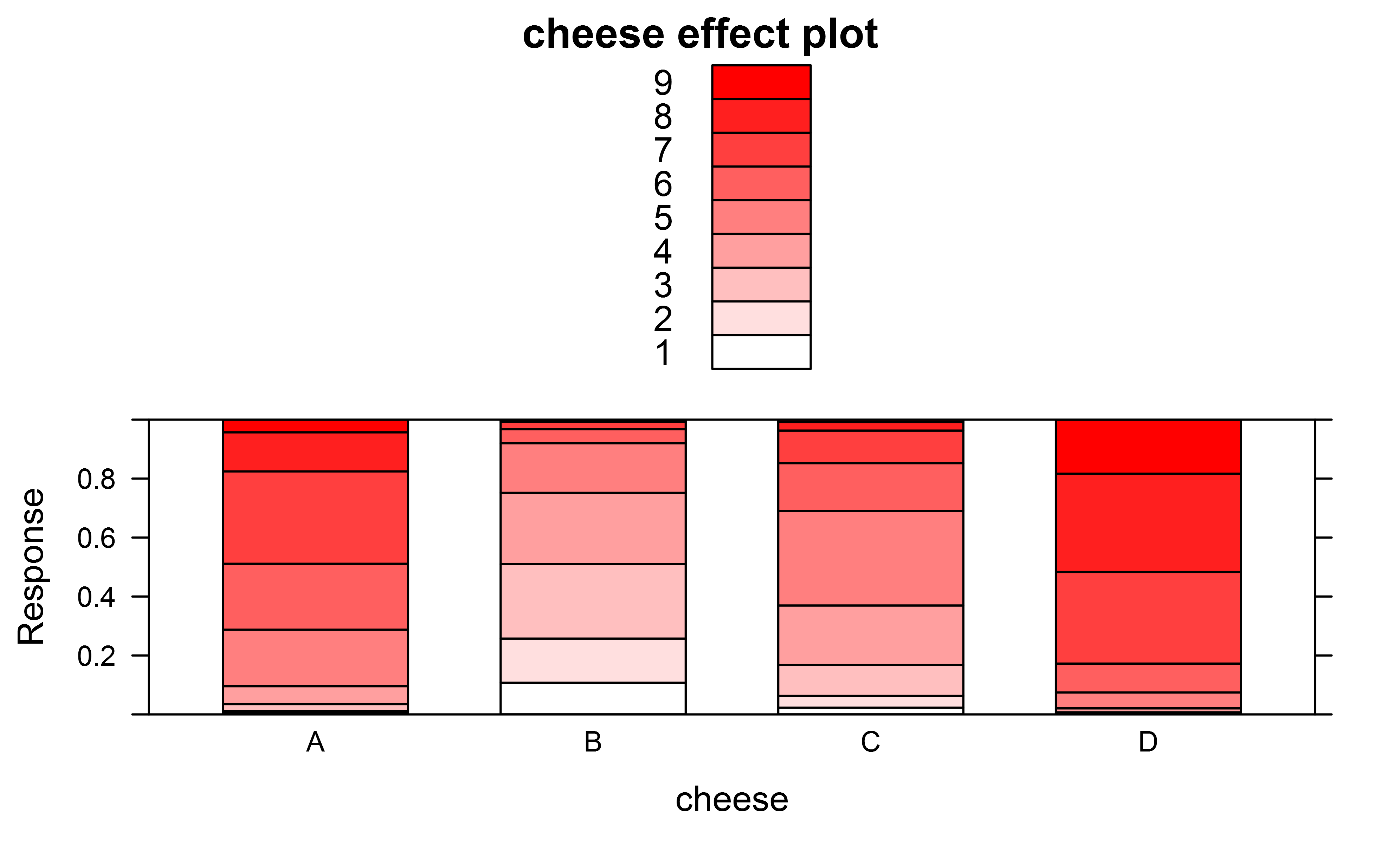
I was wondering though if from the predicted means reported by the effects package one could also plot something like the mean preference for each kind of cheese together with the 95% conf intervals on this?
EDIT: originally I also asked about how to obtain Tukey posthoc tests, but in the meantime I found that those can be obtained using
library(multcomp)
summary(glht(fit, mcp(cheese = "Tukey")))
or using package lsmeans as
summary(lsmeans(fit, pairwise ~ cheese, adjust="tukey", mode = "linear.predictor"),type="response")
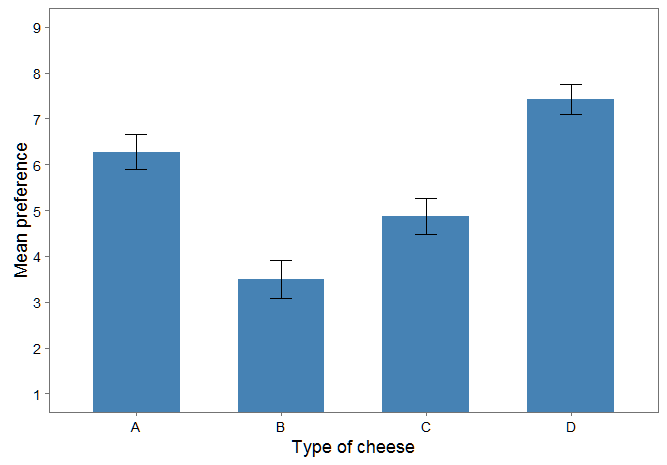
wmeanstable of summary statistics. and due to the fact that this is just a plot of summary statistics, you lose all of the data that went into making it. plots should show data not summary statistics. I think this solves your problem since you shouldn't be doing it in the first place – Selhorst