i am going thorugh this paper http://cs.stanford.edu/~quocle/paragraph_vector.pdf
and it states that
" Theparagraph vector and word vectors are averaged or concatenated to predict the next word in a context. In the experiments, we use concatenation as the method to combine the vectors."
How does concatenation or averaging work?
example (if paragraph 1 contain word1 and word2):
word1 vector =[0.1,0.2,0.3]
word2 vector =[0.4,0.5,0.6]
concat method
does paragraph vector = [0.1+0.4,0.2+0.5,0.3+0.6] ?
Average method
does paragraph vector = [(0.1+0.4)/2,(0.2+0.5)/2,(0.3+0.6)/2] ?
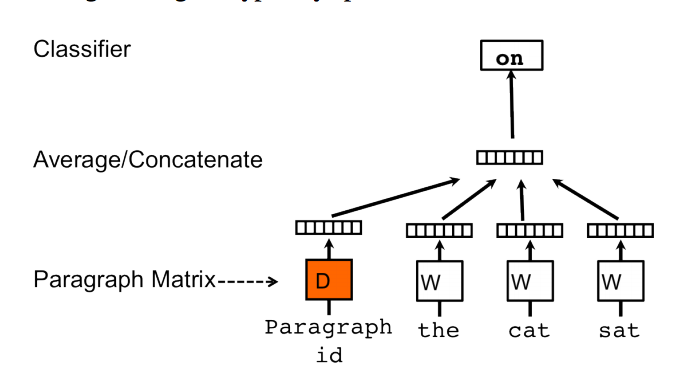
Also from this image:
It is stated that :
The paragraph token can be thought of as another word. It acts as a memory that remembers what is missing from the current context – or the topic of the paragraph. For this reason, we often call this model the Distributed Memory Model of Paragraph Vectors (PV-DM).
Is the paragraph token equal to the paragraph vector which is equal to on?